가짜연구소 9기 “AI를 잘 활용하는 개발자로 성장하기” 프로젝트에 참여하여 Datacamp의 “Machine Learning Engineer” 강의를 수강하고 해당 내용을 정리한 게시글입니다. Datacamp Machine Learning 코스 페이지
Chapter 1. Design and Exploration
End-to-End 머신러닝 설계
머신러닝의 생명주기
- 문제 정의와 데이터 탐색
- 모델 학습
- 모델 배포
- 모니터링 및 유지보수
이는 모델의 생명주기를 큰 카테고리로 간소화 한 것이며, 세부적으로 많은 단계가 존재한다.
MLOps Concept에서 배웠듯, 이러한 생명주기는 반복적이고, 한 이전 단계로 돌아가는 등 변화가 있을 수 있다.
사용자 요구사항 분석 (문제 정의)
4가지 측면으로 분석할 수 있음
- 정확성 : 고객이 비즈니스에 사용할 수 있는 수준의 목표의 성능을 달해야 함
- 신뢰성 : 고객이 사용하고자 할 때 사용 가능해야 함
- 보안성 : 민감한 정보를 안전하게 다룰 수 있어야 함
- 해석가능성(Interpretability) : 모델의 예측 결과에 대한 해석을 할 수 있어야, 의사결정자(사용자)가 본인의 지식과 합쳐 적절한 판단이 가능
데이터 수집
단순히 데이터를 모으는 것이 아니라, 데이터를 이해하는 과정이 포함된다.
데이터를 이해한다는 것은 수집된 데이터에 편향의 가능성이 있는지, 데이터 값이 정확히 무엇을 나타내는 것인지 안다는 것이다. 예를들어 여론조사 데이터를 얻었는데, 특정 연령층의 비율이 높을 때 해당 데이터에는 편향이 있을 수도 있다는 것을 알고, 데이터 탐색 단계에서 적절한 검토가 필요하다.
Exploratory Data Analysis(EDA)
EDA
- 획득한 데이터를 검토(examine) 및 분석하는 단계
- 데이터로부터 패턴을 찾는 등 인사이트를 얻고, 데이터의 특징을 파악
- 데이터 시각화, 결측치 처리, 데이터 분류 등의 과정이 포함
EDA를 위한 방법
pandas를 이용하여 분석이 가능- 학습 데이터의 클래스 개수의 불균형이 존재한다면, 모델은 많이 학습한 클래스 쪽으로 예측하려는 경향이 생김
df["column_name"].value_counts()로 한눈의 클래스 불균형을 확인할 수 있음Missing Values
- 특정 속성에 결측치가 많으면 그 자체로 모델에 오류를 일으키고, 적절히 처리하지 않을 경우 특정 케이스에만 들어맞거나 편향된 예측을 하게될 수 있음
df.isnull()로 컬럼별 N/A수 확인 가능Outliers (이상치)
- 일반적인 데이터값과 크게 벗어난 값을 지칭
- 일반적으로 측정 오류, 잘못된 입력, 매우 드문 경우에 이러한 이상치가 발생
- 다른 데이터보다 강하게 영향을 미쳐 모델이 학습하는 패턴에 왜곡을 줄 수 있음
- 박스 플롯이나, IQR을 통해 이상치를 검출할 수 있음
데이터 시각화
- 데이터의 경향성, 이상치 등을 한눈에 확인할 수 있음
EDA 목표
- 데이터의 패턴을 파악, 경향성등을 파악하여 가설 설정에 참고
- 결측치, 이상치를 확인하여 적절한 조치
- 데이터가 현실을 잘 반영하는지 검토
Data Preparation (데이터 처리)
EDA에서 얻은 인사이트를 바탕으로, 모델의 성능을 저하할 수 있는 요소를 적절히 처리하는 과정
결측치 처리
결측치는 그 자체로 머신러닝 모델에 오류를 일으키기 때문에 반드시 적절한 처리가 필요
- 결측치가 많은 row 또는 column을 제거
df.drop()또는df.dropna(how="~~")를 통해 수행가능
- 결측치의 비율이 높지 않은 경우 다양한 방식으로 처리 가능
- 데이터에 중복값이 존재하면 모델 학습에 도움이 되지 않거나 bias의 원인이 되기도 함
- 일반적으로 유니크한 ID 값을 기반으로 중복값이 있다면 삭제
- pandas에서는
df.drop_duplicates()로 처리 가능Chapter 2. Model Training and Evaluation
Feature Engineering
Feature engineering은 데이터 준비 과정 후에 진행되며, 일부는 동시에 진행할 수도 있다.
- ML 모델의 성능을 높일 수 있는 feature를 추출하는 과정
- 기존 feature를 수정하거나, 완전히 새로운 feature를 설계할 수 있음
- 좋은 feature를 많이 만들면 문제를 단순화할 수 있고, 이를 통해 더 단순한 ML 모델로 정확한 예측이 가능. (오컴의 면도날) 이를 통해 학습, 배포, 유지보수를 더 쉽게 할 수 있고, 모델에 따라 interpretability를 높일 수 있음
Normalization
- 숫자형 feature를 [0, 1]로 스케일링하는 과정
- feature의 스케일이 서로 다를 때 KNN이나 딥러닝에서는 스케일이 큰 feature가 모델에 더 큰 영향을 줄 수 있어, 이를 정규화하는 과정
Standardization
- feature의 데이터 분포를 평균 0, 표준편차 1의 정규분포로 만드는 과정
- feature를 정규분포로 만들면, 분포를 추정하는 SVM, Linear Regression과 같은 모델에서 유리함
좋은 feature를 판단하는 방법
- 절대치보다는 상대치가 유리
- 도메인 지식으로 판단했을 때, 관련이 있다고 생각되는 feature
- 다른 features가 포함하지 못하는 데이터의 특성을 포함하는 feature
- feature 선택을 도와주는 툴을 모아놓은 라이브러리
Exercise
- test set을 normalize할 때는
fit_transform이 아니라transform을 써야함 - 가장 단순한 설명이 최선이다 라는 원칙
- 모델을 선택할 때는 단순한 모델을 선택하는 것이 더 좋다는 원칙
이는 단순히 간결한게 좋다는 것 뿐만 아니라, 결론이 단순할 수록 다른 문제에 대입하여 예측하거나, 다른 요소를 추가하면서 발전시키기에 용이하기 때문이다. 또한 복잡한 모델은 더 많은 추론 시간과 재학습 비용을 요구하기 때문에 모델의 경제성 측면에서도 중요하다.
Modeling options
Logistic Regression: 클래스간의 경계면을 판단하는 모델Support Vector Classifier: 각 클래스의 공간적인 면(plane)을 찾는 모델Decision Tree: 데이터를 분류하는 최적의 rule을 찾는 모델Random Forest: 여러개의 Decision Tree를 합쳐서 판단Other models
조금 더 복잡한 알고리즘을 사용하는 모델들도 있다.
- 딥러닝 모델
KNNXGBoost
오컴의 면도날에 의하면 우선은 단순한 모델로 시작하되, 단순한 모델로 문제를 풀기 어렵다고 판단될 때 복잡한 위 모델들로 대체하는 것이 좋다.
Trainig principles
- 데이터 준비
- Feature Engineering이 잘 되어있으며, 모델이 받아들일 수 있도록 정제되어있어야 함
- 데이터 분리(split)
- 모델의 예측 결과는 각 클래스에 대한 확률
- 일반적으로 가장 높은 가능성을 가지거나, 특정 threshold를 넘은 클래스를 예측 결과로 선택함
MLFlow를 이용한 실험 로깅
MLFlow
모델을 개발할 때는 가설 검증, 하이퍼 파라미터 조절 등, 정말 많은 테스트를 진행한다. 각 모델 실험마다 하이퍼 파라미터, 선택된 feature, 모델 알고리즘 등이 서로 다르다. 이러한 수많은 실험을 기록/추적하는 것은 어려운 일이기 때문에, 실험 추적을 위한 별도의 Tool을 사용하는 경우가 많다.
MLFlow는 대표적인 오픈소스 머신러닝 관리 라이브러리로, 실험 추적부터 모델 저장 및 배포까지의 기능을 지원한다.
MLFlow로 실험하기
mlflow.set_experiment()- 실험의 이름을 함께 지정 가능
with mlflow.start_run():- 파이썬의 with문을 사용하여 MLFlow가 관리할 블록을 선언
mlflow.log_param()- 블록안에있는 하이퍼 파라미터, feature, 모델 파라미터, 출력 결과등을 모두 저장
mlflow.get_run(run_id)
대표적으로 Standard accuracy(정답 예측 / 전체 예측)을 사용하지만, 데이터의 분포가 불균일할 경우 모델의 정확성을 나타내지 못할 수도 있기 때문에, 적절하게 선택해야 한다.
Confusion matrix
- 모델의 각 클래스별 예측 결과를 보여주는그리드 형태로 보여주는 matrix
- TP, FP, FN, TN으로 구성
Balanced accuracy
- (TP + TN) / 2
- 이진분류에서 standard accuracy 보다 좀 더 정확히 평가할 수 있는 metric
- 두 클래스가 불균일할 때 클래스가 적은 쪽의 accuracy에 더 높은 가중치를 부여
Cross validation
- 모델의 성능을 평가하는 견고한 방법으로, 데이터를 학습 및 테스트 데이터로 분리할 때 여러번의 분리 결과에 대해 각각 테스트를 하여 모델 성능을 평균내는 방법
- 그중
k-fold cross-validation은 데이터셋을 데이터를 ‘k’개의 그룹으로 나누고, 테스트 데이터셋의 크기를 1/k개로 지정하여, 각 실험마다 테스트 데이터셋이 겹치지 않도록 하여 데이터를 분리한다.
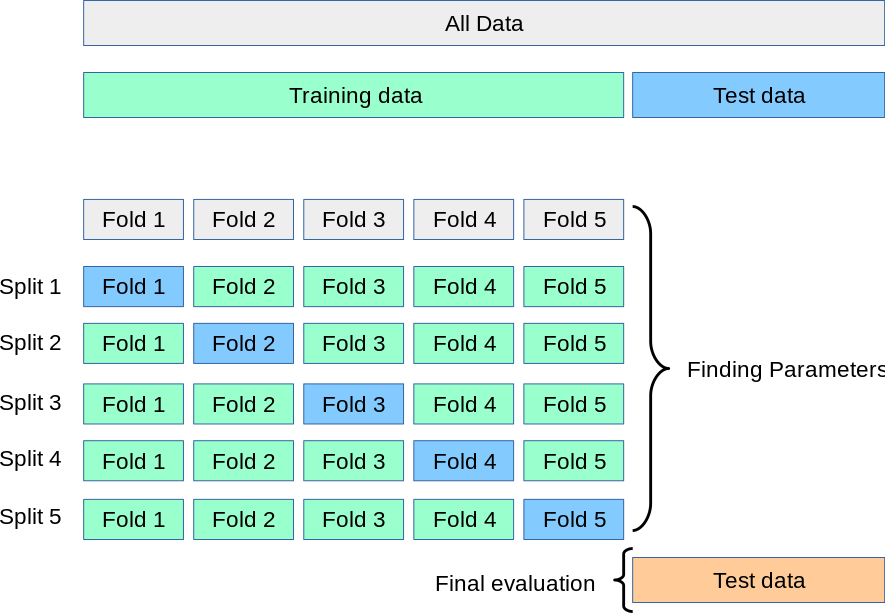 출처 : https://scikit-learn.org/stable/modules/cross_validation.html
출처 : https://scikit-learn.org/stable/modules/cross_validation.html
Cross validation usage
sklearn.model_selection라이브러리에서KFold, cross_val_score을 통해 K-fold cross validation을 수행할 수 있음
Chapter 3. Model Deployment
모델 테스트
모델의 학습을 완료한 후 Deployment를 위한 단계
테스트 항목
아래와 같은 내용을 테스트 해야 한다.
- 오류 없이 모델이 동작하는지
- 목표한 성능을 달성했는지
- 추론시간이 목표에 부합하는지
Unittest (단위 테스트)
- 극한값, 이상 상태 등의 데이터를 이용해 진행하는 테스트를 단위 테스트라고 한다.
- 파이썬은
unitteset라는 빌트인 라이브러리를 지원unittest.TestCase클래스를 상속받아, TestCase의 서브클래스를 생성할 수 있음setUp메서드에서 테스트에 사용할 모델 및 데이터를 설정하고,test로 시작하는 메서드에서 검사를 진행할 수 있음
unittest.TestCase는 유효값 체크를 위한 여러 빌트인 메서드를 제공assertEqual(pred, true): 두 값이 동일한지 체크assertIn([pred, [min, max]]): 결과가 정해진 범위 안에 들어오는지 체크
그 외 사용법은 공식문서 등을 통해 공부하자
테스트의 장점 (TDD의 장점)
- 개발 과정의 신뢰성 증가
- 개발자들이 코드 동작에 대해 덜 신경써도 되기 때문에 개발 사이클의 효율성이 증가
- 버그의 위험 감소
- 배포 버전의 성능 보장
Architectural components in end-to-end machine learning frameworks
Feature stores
Feature 엔지니어링 및 feature 선택을 효율적으로 하기 위해서는 Feature store를 구축하는 것이 좋다.
feature store는 다른 모델 알고리즘을 사용할 때, feature를 재사용함으로써 실험의 일관성을 보장하는 역할을한다. 이를 위해 feature store에 저장된 feature는 모델에 즉시 투입가능하도록 standardization 등이 완료된 형태여야 한다.
feature가 생기거나, 병합되는 경우가 많으므로 feature store는 버전 관리가 가능한 데이터베이스이어야 한다.
Feast
- Feature store 구축을 위해 자주 사용되는 오픈소스 도구
- ML features를 위한 통합된 관리, 저장, 서빙 등의 기능을 제공
- 서로 관련된 feature를 그룹핑하여 메타데이터를 추가한 feature set을 단위로 관리
Feast 사용법
Entity,Field를 이용해 엔티티 이름과 속성 지정- 데이터가 직접 들어있는 파일을
FileSource로 지정- 로컬 파일, 원격 데이터베이스 등 다양한 옵션을 제공
- 이 때 timestamp를 지정해서 시계열 데이터를 용이하게 관리할 수 있음
FeatureView를 통해 로드된 데이터셋의 View를 생성- Entity와 FeatureView 준비되었다면
FeatureStore를 선언하고apply메서드를 통해 FeatureView를 Store에 등록
Model registries(모델 레지스트리, 저장소)
- 원하는 모델을 신속하게 로드할 수 있도록 모델을 저장해두는 저장소
- 모델의 버전 관리 기능을 포함
- 모델의 정보 성능과 같은 메타데이터를 저장해 원하는 모델을 쉽게 검색할 수 있도록 함
- MLFlow를 Model registriy로 활용 가능
Packaging and containerization
- 모델을 환경에 상관 없이 독립적으로 실행 가능한 모듈로 만드는 과정
- 일반적으로 containerization을 통해 컨테이너로 만들어 사용
Docker
- container를 기반으로 하는 배포 플랫폼
- 애플리케이션을 실행 환경과 함께 패키징하여 독립 실행이 가능한 이미지를 생성
DockerFile 구축
- 이미지를 생성하기 위한 모든 명령어가 포함된 텍스트 문서
- OS 설치, 파일 복사, 디렉토리 이동, 라이브러리 설치(pip), 포트 노출, 환경 변수 설정 등의 명령어가 포함됨
이미지 생성 및 배포
docker build를 통해서 DockerFile로 이미지 빌드- 이미지를 구분하고 쉽게 관리하기 위해
tag를 이용Best practices
- 이미지의 보안에 유의할 것
- 이미지에 민감한 정보가 포함되어서는 안되며, 다른 이미지를 이용할 경우 반드시 검증된 이미지만 이용
CI/CD
CI/CD 원칙
Continuous Integration(CI)
- 코드를 머지할 중앙 레포지토리 마련 (배포 레포지토리와는 달라야 함)
- 버그 확인을 위한 자동 테스트 과정을 포함
Continuous Deployment (CD)
- 배포 레포지토리가 업데이트 되면 자동으로 배포가 이루어 져야함
- 종종 CI와 결합되어 사용
머신러닝의 CI/CD
- 재학습된 모델의 자동 배포, 자동 성능 테스트, 자동화된 룰 기반 배포등이 포함
- Data drift를 방지하기 위한 모델 재학습 및 재배포가 효율적으로 이루어질 수 있도록 함
EB (AWS Elastic Beanstalk)
- AWS에서 제공하는 배포 서비스
eb create <ENV_NAME>으로 환경 생성eb deploy로 환경 배포, 이 때 애플리케이션은 컨테이너eb open으로 배포된 애플리케이션을 웹 브라우저로 실행EB의 대체 서비스
여러가지 이유로 EB를 제외한 다른 서비스를 이용해야 할 경우 다음의 것들을 고려해볼 수 있다
- Azure Machine Learning
- GCP App Engine
- Kubernetes
- 컨테이너 오케스트레이션 시스템
- 러닝 커브가 필요하지만, 모델 배포를 정밀하게 설정할 수 있다
이 외에도 여러가지 서비스 및 도구들이 존재하지만, 중요한 것은 배포를 안전하고, 효울적으로 반복할 수 있도록 해야한다는 것을 기억하자
Chapter 4. Model Monitoring
Monitoring and visualization
모델의 유효성을 보장하기 위해 모델의 성능을 계속 모니터링 해야함
- 모니터링의 종류
- 파이썬의 빌트인 패키지인
logging을 사용하여 로그파일에 로그를 남길 수 있다 logging.basicConfig()등 설정 메서드를 통해 로깅 설정logging.info()를 통해 텍스트 형식으로 로깅- 로그 파일은 이후 파이썬에서 로드하여 텍스트 처리를 통해 시각화 가능
Visualization
- 일정 기간의 모델의 성능을 검사하는 것에 유용
matplotlib,seaborn등의 시각화 라이브러리를 이용시각화 예시
- line graph : 시간에 따른 성능 시각화에 유용
- balanced accuracy : 모델의 예측에 대한 고객의 최종 판단 데이터가 있다면, 를 metric으로 사용하여 모델의 예측 성능에 대한 시각화가 가능
Data Drift
Data Drift : 시간에 따라 모델에 입력되는 데이터의 통계적 특성이 변하는 현상 예를 들어 30년 전과 지금은 인구학적 통계가 달라, 사람들에 대한 정보의 통계적 특성이 달라졌을 확률이 높다. 이 때 30년 전 데이터셋으로 학습한 모델은 현재 데이터에 대한 성능이 낮을 수 있다.
Data Drift로 인해 모델의 성능이 반드시 낮아지는 것은 아니지만, 가능한 최신의 데이터를 반영하는 것이 현재의 현실을 정확히 반영할 가능성이 높다.
The Kolmogorov-Smirnov test
- Data Drift를 확인하기 위한 여러가지 통계적 방법 중 하나로, KS 검정이라고 부른다.
- 두 데이터셋의 분포가 동일한 분포를 따르는지 검정하는 방법
scipy.stats라이브러리의ks_2samp()함수를 통해 KS 검정을 할 수 있다.- 검정 통계량(test statistic), p-value를 반환
- p-value는 유의수준에 따라 가설을 기각할 것인지 결정
p-value
p-value : 귀무 가설이 맞다고 가정할 때 해당 검정 통계량 보다 크거나 같은 값을 얻을 수 있는 확률. 즉, 귀무가설이 맞다고 가정할 때, 귀무가설에 해당하는 결과(또는 더 극단적인 결과)가 일어날 확률.
예를들어 p-value가 0.05라는 것은 귀무 가설이 맞다고 가정했을 때, 지금과 같은 결과가 나올 확률이 5%라는 것이다. 그 만큼 현재의 통계량이 특이하다는 뜻이며, 귀무가설을 기각하는 근거가 된다.
그 외의 방법
- Population Stability Index (PSI)
- 데이터의 특정 범주형 값 컬럼에 대한 data drift를 검사
- Evidently
- 오픈소스 파이썬 라이브러리
- data dritf에 대한 견고한 테스트 지원 및 모델 성능에 대한 추적 기능 제공
- NannyML
- 모델에 새로운 데이터를 반영하는 과정
- 새로운 데이터가 충분하다면 모델 재학습을 고려할 수 있다.
- 데이터가 충분하지 못할 경우, 오래된 데이터의 일부를 점진적으로 교체할 수 있다.
Feedback loop, re-training, and labeling
Feedback loop
- 모델의 예측 결과, 성능 데이터 등 시스템의 다양한 출력값이 다시 시스템에 입력으로 사용되는 시스템 아키텍처
- 시스템에 다시 입력된 데이터는 모델이 시간이 지나도 계속 적응하고 진화할 수 있도록 미래의 행동을 안내하는데 사용
- 다양한 모델 모니터링 기술을 통해 이러한 시스템의 출력을 기록 가능
- Data drift등 변화에 대해 자동으로 끊임없이 모델이 적응/진화하도록 함
Feedback loop 구현
수동 Feedback loop
- 앞서 배운 Data Drift를 감지하고, 이에 따라 재훈련을 수행하는 방법이 포함
- 재훈련시 도메인 지식, 설문조사 등의 방법을 통해 수동으로 새로운 label을 추가하여 모델의 정확한 예측을 도울 수 있음
자동 Feedback loop
- Online learning - 주기적으로 새로운 데이터에 대한 재학습을 진행하도록 구현
이 외에 다양한 방법론이 존재
- 예시
- 모델의 출력이 입력에 영향을 주는 경우, Feedback loop가 반복될 수록 bias가 커지는 문제가 발생할 수 있음 (ex. 알고리즘 폭주)
- 자동 Feedback loop일수록 이러한 위험이 증가하기 때문에, 이러한 사항을 고려하여 지속적 모니터링이 필요함
- 사용자, 이해관련자가 모델을 사용할 수 있도록 안전한 경로를 통해 모델을 배포하는 것
- 인터넷 연결이 자유롭다면 HTTP를 통해 쉽게 데이터와 결과를 주고 받을 수 있다.
- 그러나 인터넷을 사용할 수 없거나, 민감한 정보가 포함되어있어 보안 수준이 높다면 이에 맞는 적절한 배포 방법이 필요하다.
On-device serving
- 모델이 사용자의 기기 또는 애플리케이션에 통합되어있는 형태로 서빙
- 장점
- 보안 수준이 높음
- 네트워크로 인한 지연이 없음
- 더 많은 분야에서 사용 가능 (네트워크를 사용할 수 없는 환경)
- 단점
- Pruning : 모델의 성능을 유지하면서 모델의 파라미터 크기를 최소화하여 모델을 더 가볍고 빠르게 하는 기법
- Transfer Learning : 큰 모델을 사용하는 대신, 작은 모델을 특정 도메인의 task에 맞게 파인튜닝하여 사용하는 기법
- On-device 특화 프레임워크 사용 : ONNX, TensorFlow Lite 등
위 기법들로는 목표한 성능을 달성하지 못할 수 있기 때문에, 부여된 태스크에 맞는 많은 연구가 필요하다.
학습 소감
알게 된 점
SelectFromModel, mlflow, Feast와 같이 사용해본적 없는 라이브러리, 도구들을 직접 실습해보며 유용성을 알 수 있었습니다.
모델 배포 이후 모니터링, Feedback loop의 구체적인 방법에 대해 알게 되었습니다.
on-device 모델이 왜 필요한지, 모델링 시 어떤점에 주의해야하는지 알게 되었습니다.
느낀점
사실 머신러닝을 오랜만에 접하는데, 잊고 있었던 데이터 처리 관련 주의점, 오컴의 면도날 원칙 등을 다시 느끼게 되었습니다.
딥러닝에서는 이러한 처리를 덜 중요하게 느끼는 경향이 있어서 경시하기 쉬운데, 온디바이스와 같이 제한된 성능의 모델을 사용해야할 때 특히 이러한 데이터 처리, feature 엔지니어링을 잘 다루어야 할 것 같습니다.
궁금한 점
Chapter 2의 Architecture components가 정확히 무엇인지 정확히 이해하지 못했습니다.