Aivle Til 230224 머신러닝 5
title: AIVLE TIL (‘23.02.24) 머신러닝 (5) date: 2023-02-24 13:41:54.462 +0000 categories: [에이블스쿨] tags: [‘aivle’] description: 앙상블 알고리즘과, 지금까지 배운 것을 바탕으로 전체 모델링 사이클을 실습해보자 image: /assets/posts/2023-02-24-aivle-til-230224-머신러닝-5/thumbnail.png
오늘 배운 것
하이퍼파라미터 튜닝 (어제부터 계속)
Grid Search와 Random Search의 조합 고려
만약 적절한 하이퍼파라미터 값에 대한 지식이 없을 때, Random Search로 단시간 내에 로컬한 최적값을 찾고, 이후 주변 범위에서 Grid Search를 진행하는 방법을 고려해 볼 수 있다.
튜닝할 하이퍼파라미터가 여러개일 경우 가장 중요한 것부터 하나씩 탐색해가며 최적의 조합을 찾는 방향도 있다.
유의할 점 : 결국 학습 데이터에 대해 구한 예측 성능이기 때문에, 실제 평가에서 성능이 보장되지 않는다. 학습 성능이 최대치인 모델보다는 적절한 예측력을 위해 적절한 복잡도의 모델을 완성하는 것이 중요
기억해두면 좋은 속성
model.cv_results_: K-분할 CV의 결과가 딕셔너리 형태로 담겨있다.model.best_params_: 최적 파라미터 값 (최고 학습 성능을 낸 값)model.best_score_: 최적 파라미터 값일때 예측 성능
앙상블(Ensemble)
1. 앙상블 이해
- 여러개의 모델을 결합하여 하나의 강력한 모델을 생성하는 기법
- 약한 모델이 올바르게 결합하면 더 정확하고 견고한 모델을 얻을 수 있다.
- 앙상블을 이용한 알고리즘은 기계학습 경쟁에서 상위 순위를 차지하고 있어 성능 면에서 유리하다.
- 크게 보팅, 배깅, 부스팅, 스태킹 4가지 개념이 있다.
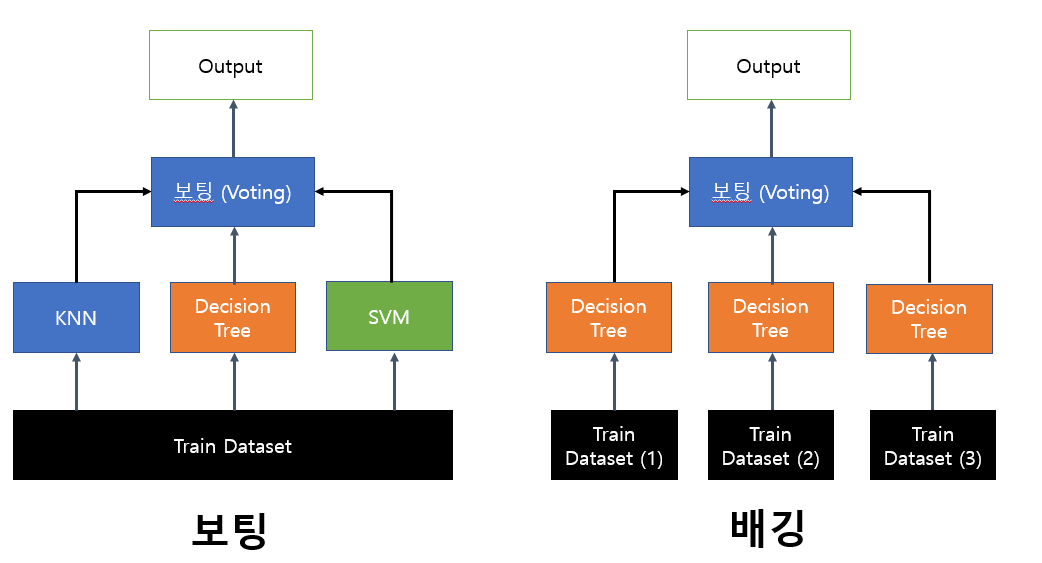
2. 보팅(Voting)
큰 모델 안에 여러개의 알고리즘 모델이 들어있어, 학습 데이터를 모델별로 각자 학습한 뒤 투표를 통해 최종 예측 결과를 결정하는 기법
하드 보팅 : 투표와 같은 방식으로 모델마다 하나의 예측 값을 선택하여, 가장 많이 선택된 예측 값을 최종 결과로 선택
소프트 보팅 : 모델마다 확률값을 도출
(예. Yes=0.8, No=0.2)각 모델이 도출한 확률값을 집계하려 최종적으로 더 높은 확률을 갖는 예측값을 최종 결과로 선택
3. 배깅(Bagging)
- Bootstrap Aggregating의 약자
- 부트스트랩이란 전체 데이터셋에서 랜덤 복원추출 샘플링을 반복하여 한 개의 데이터셋으로 부터 새로운 데이터를 계속 생성하는 방식을 말함
- 한 종류의 모델을 사용하되, 부트스트랩 한 여러개의 데이터로 각 모델을 따로 학습시켜, 학습한 모델의 결과를 집계하여 최종 결과를 선택한다.
- 분류 문제의 경우 : 보팅 방식
- 회귀 문제의 경우 : 평균 이용
랜덤 포레스트 (Random Forset)
배깅의 가장 대표적인 알고리즘
- Decision Tree 모델을 기반으로, 전체 데이터에서 배깅 방식으로 각자의 데이터를 샘플링 한다.
- 각 모델들 이 개별적으로 학습을 수행한뒤, 모든 결과를 집계하여 최종 결과를 선택한다.
하이퍼파라미터
n_estimators: 모델의 개수- 기본값은 100으로, 많이 지정할 수록 성능이 높아질 것을 기대할 수 있다.
- 그러나 학상 그런 것은 아니고, 모델 개수가 너무 많아지면 학습 속도가 느려질 수 있음을 고려해야 한다.
- Decision Tree의 하이퍼파라미터
- max_depth, max_feature 등 Decision Tree에서 사용되는 하이퍼파라미터를 똑같이 설정할 수 있다.
랜덤의 의미
- 배깅 방식으로 랜덤하게 데이터를 샘플링
- 트리를 구성할 때 분할 기준이 되는 Feature를 랜덤하게 선정
- 전체 변수가 20개이고, max_feature가 0.5일 경우 10개의 변수를 랜덤으로 선택하여 트리 분할에 이용한다.
- 즉 개별 모델마다 다른 구조의 트리가 구성된다. (하이퍼파라미터 설정 필요)
4. 부스팅
- 같은 알고리즘 기반의 모델 여러개에 대해 순차적으로 학습을 진행한다.
- 현재 앙상블 학습을 주도하는 기법으로, 배깅에 비해 성능이 좋지만 속도가 느리며 과적합의 위험이 있음
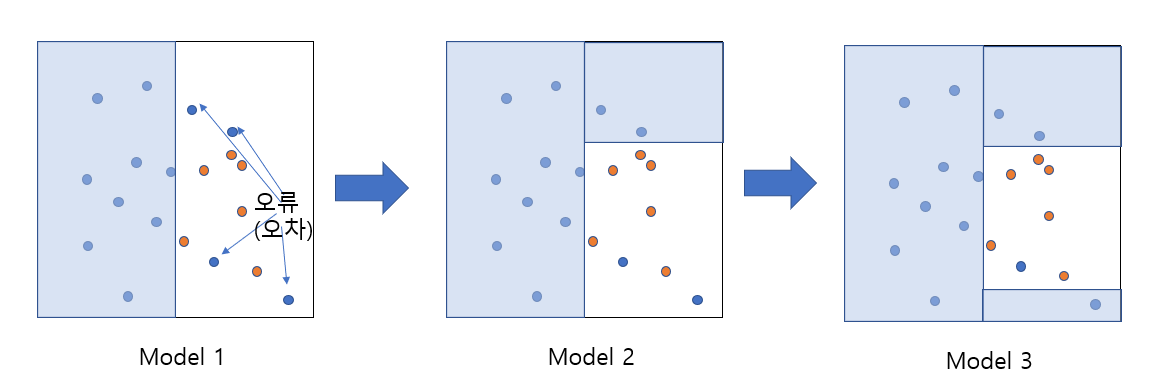
- 앞선 모델의 오차에 대한 학습을 하여, 오차를 줄여나간다.
- 오류가 전부 해결되면 학습 데이터에 대한 성능은 최상이지만, 과적합 발생의 우려가 크다
XGBoost (Extreme Gradient Boosting)
- 부스팅의 대표 알고리즘 중 하나로, Decision Tree를 기반으로 한다.
- 하이퍼파라미터의 종류가 정말 많은 것이 특징이다.
- 자세한 원리는 이번 과정에서 다루지 않는다.
주말에 추가학습으로 대략적인 원리를 이해하자!
LightBGM
- XGBoost의 장점을 계승하고, 단점을 줄이는 방향으로 개발된 알고리즘으로, XGBoost보다 학습시간이 더 짧다는 장점이 있다.
- 마찬가지로 자세한 원리는 이번 과정에서 다루지 않았다.
5. 스태킹
- 배깅과 유사하게 여러개의 모델을 각각 조합하여 예측값을 도출한다.
- 예측값을 도출하고 끝내는 것이 아니라, 예측값을 Train Date로 학습한 최종 모델을 만들어 학습을 진행한다.
- 아직까지는 현실 모델에서 많이 사용하지 않고, 미세한 성능차가 중요한 대회 등에서 사용되고 있다.
실습
- 종합실습진행
- 데이터에서 target을 선정하여 x와 y로 분리
- x에 대해 데이터 처리 진행 (불필요한 변수 drop, 가변수화, 결측치 제거 및 처리)
- x를 학습 데이터, 테스트 데이터(또는 검증 데이터)로 분할
- 필요시 x 학습 데이터에 대해 정규화 진행
- 모델별 K-Fold Cross Validation을 통해 가장 뛰어난 성능을 보일 것으로 예상되는 모델을 선정
- Grid Search를 통해 최적 파라미터 값 선정
- 학습 진행 및 예상 성능 확인
- 시각화
- 테스트 데이터에 대한 학습 및 결과 확인
모델링의 전체 사이클을 돌아보는 종합실습을 진행하였다.
과정 종료 소감
학습 목표 돌아보기
- 주어진 데이터를 탐색하고
- 분석에 용이하도록 전처리 한 후
- 여러 알고리즘의 성능을 비교해
- 가장 성능이 좋은 알고리즘을 선택한 뒤
- 하이퍼파라미터 튜닝을 통해
- 나름 최선의 모델을 완성해
- 새로운 데이터에 대해 예측하고 평가
비록 최적화된 데이터셋을 바탕으로 시키는대로 한 것에 불과하지만, 전체 모델링 과정을 수행하는 실습을 반복하며 역량을 많이 향상한 것 같다.
원래라면 한 학기를 통채로 배워도 부족할 것을 단 5일 만에 배웠으니, 깊이도 얕고 전공자의 지식에 비하면 굉장히 당연하고 시시한 것을 배운 과정이었을 것 같다.
그럼에도 모델링을 위한 최소한의 역량을 갖추었다고 자신한다. 부족한 것은 더 찾아보고, 새로운 알고리즘을 배우는 것을 통해 보완해나가도록 하자.
딥러닝 과정이 종료되고 다다음주에 시작되는 미니프로젝트에서 배운것을 최대한 활용하며 전공자 못지 않은 성과를 내어보고 싶다.