Aivle Til 230307 2차 미니프로젝트 2일차
title: AIVLE TIL (‘23.03.07) 2차 미니프로젝트 2일차 date: 2023-03-07 12:26:12.385 +0000 categories: [에이블스쿨] tags: [‘aivle’] description: 머신러닝 모델링의 한 사이클을 모두 돌아보았던 하루 image: /assets/posts/2023-03-07-aivle-til-230307-2차-미니프로젝트-2일차/thumbnail.png
무엇을 했나?
미션
- 악성 사이트 탐지 모델링
목표
- HTML 스크립트를 바탕으로 해당 사이트가 악성 사이트인지 여부를 탐지한다.
학습 목표
비즈니스의 이해 -> 데이터 탐색 ->데이터 전처리 -> 모델링 -> 평가 -> 배포
알고리즘 선택 -> 하이퍼파라미터 튜닝 -> 모델 완성
- 새로운 도메인의 학습 데이터를 탐색하고
- 분석에 용이하며 좋은 성능을 낼 수 있도록 데이터를 전처리 한 후
- 최적의 머신러닝 모델을 완성한다.
데이터
Raw data
HTML 코드와 악성 사이트 여부로 구성된 엑셀 파일
데이터 탐색 및 전처리의 연습용 데이터로, 실제 분석에 사용되지는 않았다.
Train data
전처리된 데이터와 악성 사이트 여부로 구성된 csv 파일
feature selection과 결측치 처리등의 전처리가 필요하다.
프로젝트 수행
0. Raw Data로 부터 필요한 데이터 추출
- HTML 코드를 bs4 모듈로 탐색하고 필요한 데이터를 추출하였다.
BeautifulSoup
- 파이썬에서 HTML 코드를 파싱해 다룰 수 있게해주는 라이브러리이다.
- 웹 크롤링에서 이미 다룬 적 있으므로 자세한 설명은 생략한다.
openpyxl
- 파이썬에서 엑셀 파일을 읽고 쓸 수 있도록 하는 라이브러리이다.
- 엑셀은 .xlsx, .xlsm, .xlxt 등 다양한 확장자가 있는데, pandas가 제공하는 read_excel만을 사용할 경우, 확장자를 제대로 처리하지 못해 에러가 발생할 수 있다.
- 이때 openpyxl을 엔진으로 선택하면 에러없이 엑셀파일을 불러와 df 형태로 저장할 수 있다.
1
df = pd.read_excel('파일명', engine='openpyxl')
re 내장 라이브러리
- python의 내장 라이브러리인
re는 정규식을 이용한 연산을 지원하는 라이브러리이다. - 그 중
re.compile()함수에 정규식이나 간단히 문자열을 매개 변수로 전달하면 정규식을 통해 문자열을 서칭할 수 있는 정규식 객체가 반환된다. - HTML 텍스트에서 특정 문자를 찾고 싶은 경우 사용할 수 있다.
1
matches = html.find_all(string=re.compile(' '))
1. 데이터 탐색
- 공선성 제거 및 학습에 도움이 되지 않는 Feature를 걸러내기 위해 이번에는 탐색에 많은 시간을 투자했다.
단변량 탐색
각각의 feature에 대해 boxplot으로 분포를 확인하고, 이상치가 어떠한 값을 갖고 있는지 탐색하였다.
대부분의 feature가 오른쪽으로 긴 꼬리(및 이상치 후보)를 갖고 있음을 확인할 수 있었다.
왜도와 첨도를 수치화하면 더 좋았겠지만 아쉽게 시간 관계상 진행하지 못하였다.
이변량 탐색
feature간 상관관계 분석을 진행하여 상관관계가 매우 높은 일부 feature를 제거하였다.
scatter plot으로 요인과 타겟 및 요인끼리의 분포를 관찰하였으며, 이를 통해 변수를 합치거나 연산을 통해 새로운 변수를 만드는 처리를 하였다.
- 연산을 통해 새롭게 변수를 만들면 당연히 어느정도의 공선성이 생기므로 기존 변수를 제거하는 방법도 좋았을 것 같다. 시간이 되면 두가지 버전으로 비교 분석을 하는 것이 좋을 것 같다.
2. 데이터 전처리
단변량 분석을 통해 파악한 중복 변수 및 의미 없는 변수를 제거하였다.
모델링을 위해 object 자료형을 갖는 범주형 데이터를 숫자형으로 변환하였다.
불균형 데이터로 인한 학습 치우침을 막기 위해 stratify를 적용하여 학습 데이터와 검증 데이터를 분류하였다.
1
2
3
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, stratify=y)
- 단변량 분석결과 대부분의 변수에 이상치가 많이 존재함을 확인했으므로 Robust Scailing을 진행하였다.
- Robust Scaling은 사분위수와 중앙값을 통해 스케일링을 하며, 다른 방법에 비해 이상치에 덜 민감하다는 장점이 있다.
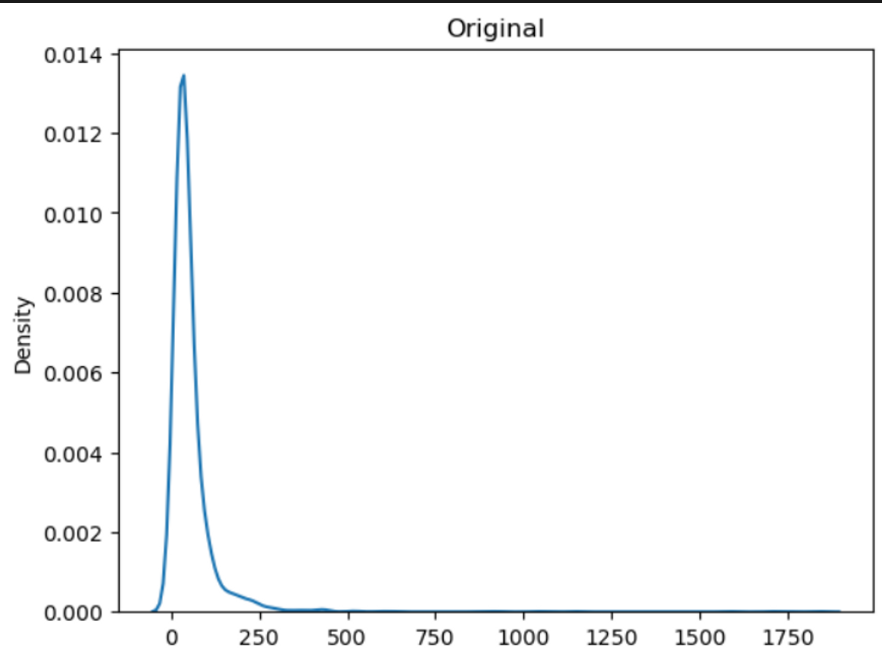
3. 알고리즘 선택
가능한 많은 알고리즘을 테스트하기 위하여 함수 및 for문을 사용했다.
return을 시각화가 가능한 형태로 받았으면 시각화를 통해 정리가 가능하겠지만, 미처 거기까진 생각하지 못하여서 accuracy 및 F1-score를 비교하는 정도를 진행하였다.
테스트 결과는 XGBoost ≒ LightGBM ≒ GradientBoosting > RandomForest » 기타모델로 앙상블 알고리즘에서 매우 높은 성능을 보였다.
4. 하이퍼파라미터 튜닝
약간이지만 더 높은 성능 점수를 기록한 XGBoost 알고리즘에 대해 GridSearch를 진행하였다.
먼저 learning rate를 서치하여 고정한 뒤, max_depth를 서치하였다.
XGBoost는 튜닝할 수 있는 요인이 많기 때문에 관련해서 더 학습한다면 조금 더 개선된 모델을 만들 수 있을 것이다.
추가학습
ydata-profiling
- Automated EDA를 지원하는 패키지이다.
- EDA에 소모되는 많은 시간을 줄이기 위해 이 과정을 자동화 및 요약 정보를 사용자에게 출력해준다.
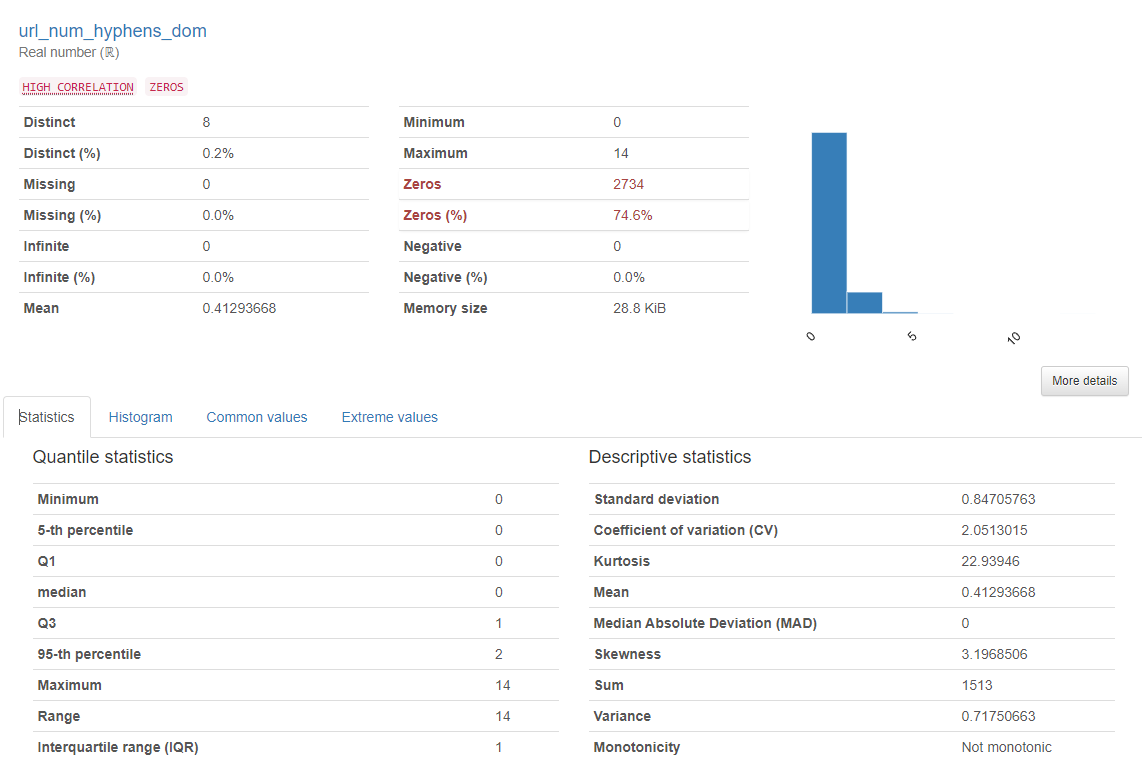
- 기본 통계량, 집계 결과를 제공한다.
- 어떤 변수와 높은 상관관계를 갖는지 역시 제공한다.
- 사진을 첨부할 수는 없지만, Interaction을 시각화한 그래프와 상관계수 Heatmap까지 제공한다.
정말 중요한 변수이고 조작이 필요하다면 직접 데이터 탐색을 수행해야겠지만 데이터를 훑어보고 특징을 파악하는 정도라면 정말 유용하게 쓰일 것 같은 라이브러리이다.
소감
좋았던 점
1일차에 데이터 탐색이 부족했던 것이 아쉬웠는데, 이번에는 많은 시간을 소요하고 인사이트 역시 도출할 수 있었다.
Robust Scaling이라는 새로운 방법을 시도해보았다.
거의 처음으로 모든 모델링 과정을 온전히 수행하였다.
아쉬웠던 점
하이퍼파라미터에 대한 지식이 부족해 완전히 최적화된 파라미터값은 찾지 못한 것 같다. (성능 점수의 큰 차이 없음)
강의의 1/3 정도는 강사님의 설명이 있었는데 실습을 진행하기 바빠 설명을 거의 듣지 못했다. 늦어도 이번 주말에는 중요 부분이라도 강의를 시청하면서 놓쳤던 부분을 들어야 할 것이다.