Aivle Til 230328 언어지능 딥러닝 2
title: AIVLE TIL (‘23.03.28) 언어지능 딥러닝 (2) date: 2023-03-28 15:55:15.857 +0000 categories: [AIVLE] tags: [‘aivle’] description: LSTM과 GRU 구조 및 파라미터 계산 image: /assets/posts/2023-03-28-aivle-til-230328-언어지능-딥러닝-2/thumbnail.png
오늘 배운 것
RNN 모델의 파라미터 계산
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
simple_rnn (SimpleRNN) (None, 20, 16) 368
simple_rnn_1 (SimpleRNN) (None, 32) 1568
flatten (Flatten) (None, 32) 0
dense (Dense) (None, 1) 33
=================================================================
Total params: 1,969
Trainable params: 1,969
Non-trainable params: 0
_________________________________________________________________
※ Input Layer의 shape는 (20, 6)이다.
우선 파라미터의 수란 업데이트 되어야 할 가중치 수를 의미한다. 즉 Fully Connected 되어있을 경우 n개의 Input에서 m개의 Feature를 생성하기 위해 n * m의 파라미터가 필요하다.
- RNN 계산에서 Input은 크게 두 종류이다.
- 이전 레이어의 Input
- 현재 레이어 이전 시점(t-1)의 hidden state
- 여기에 편향이 더해진다.
생성할 Feature는 hidden state의 노드 수와 같다.
- 종합하면
Input의 수 * hidden state의 수가 파라미터의 개수가 된다.
simple_rnn (SimpleRNN)
- Input = 6 + 16 + 1
- Hidden state = 16
- Params = 23 * 16 = 368
simple_rnn_1 (SimpleRNN)
- Input = 16 + 32 + 1
- Hidden state = 32
- Params = 49 * 32 = 1568
※ 시점의 수를 계산하지 않는 이유는 시점에 관계 없이 동일한 가중치를 사용하기 때문이다.
LSTM (Long Short Term Memory)
figure : colah - Understanding LSTM Networks
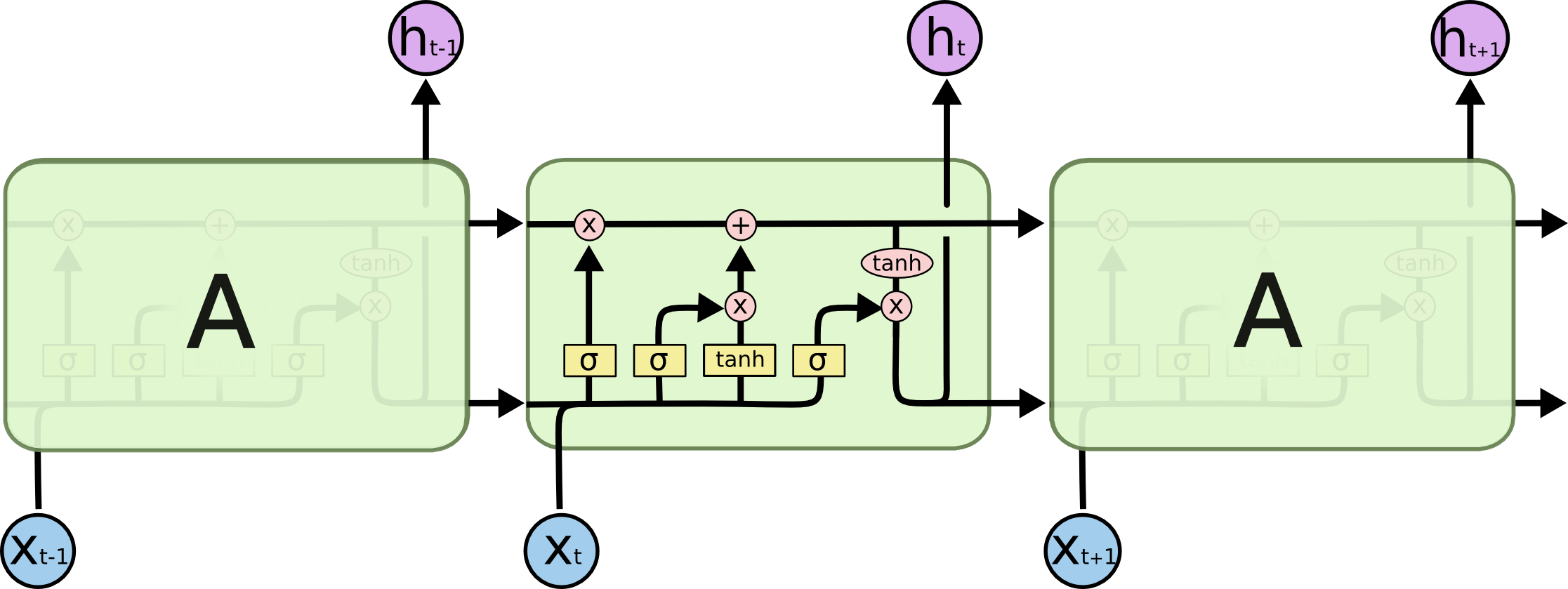
- 기본적으로 RNN의 구조에서 ‘기억(memory)’의 역할을 하는 Cell state를 추가한 형태이다. Cell State의 정보를 생성, 유지 및 관리하기 위해 gating이라는 기법을 사용하였다.
즉 어떻게 memory를 구현하였는지 이해하는 것이 LSTM을 이해하는 핵심이다.
- 구조를 외운다기보다는 어떤 연산이 어떤 역할을 하는지를 이해하는 것이 추후 모델의 학습에 더 도움이 된다.
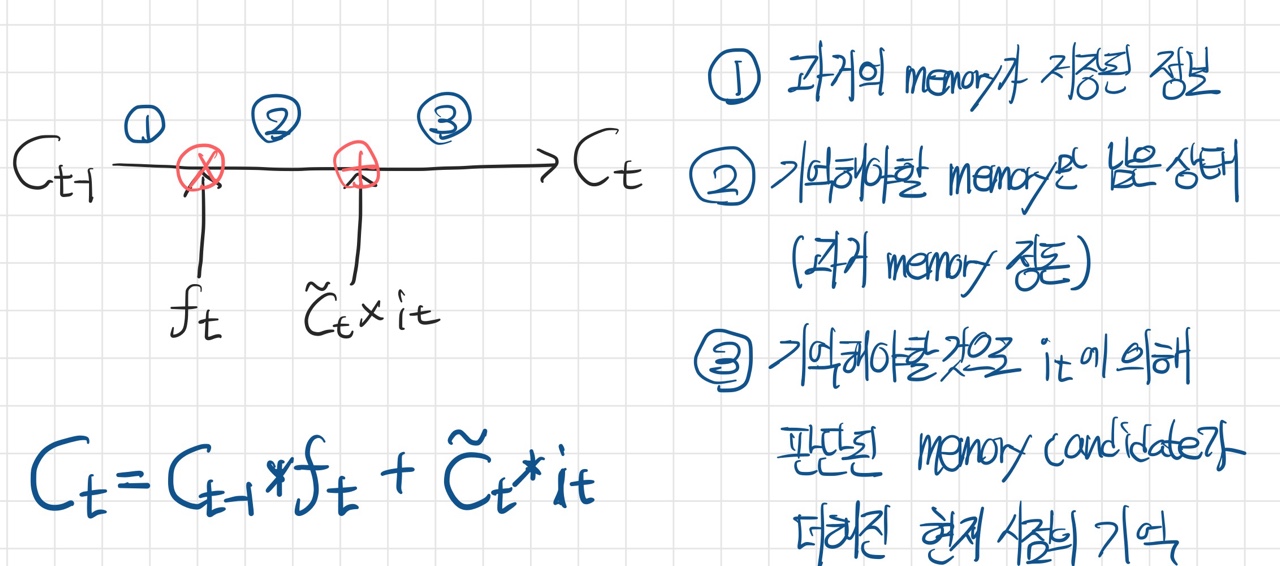
1. Cell State
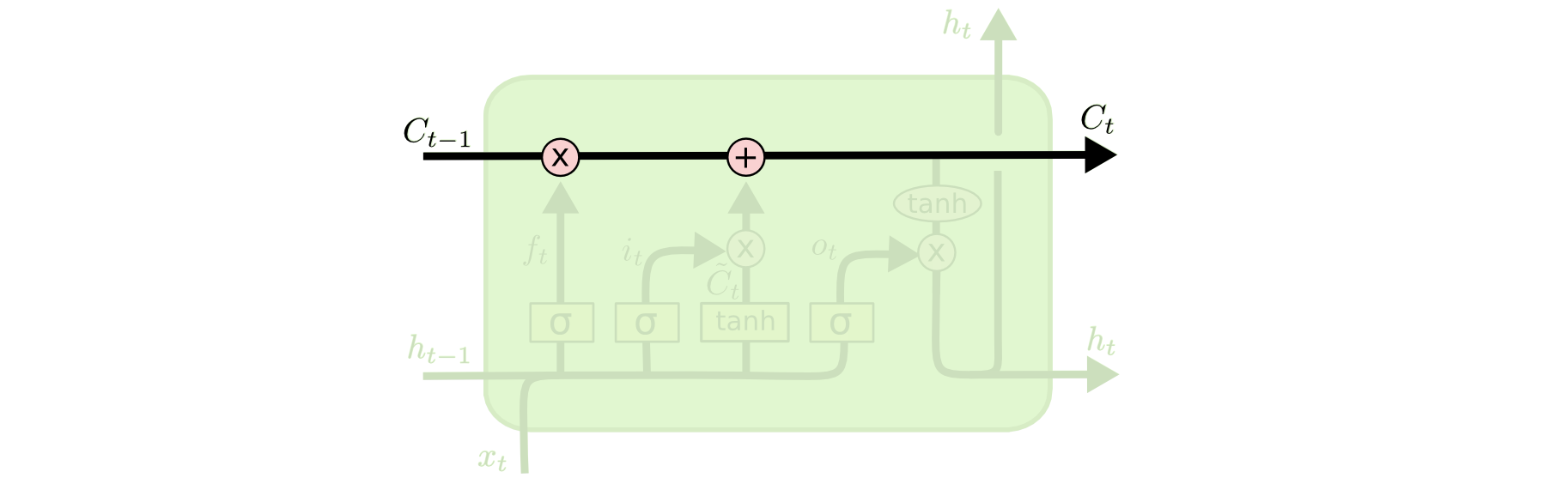
- 앞서 말했듯, 기억의 역할을 한다. 외부로 출력되지 않고, 내부적으로 처리되면서 다음 레이어로 전달될 hidden state를 생성하기 위해 사용된다.
2. Forget gate
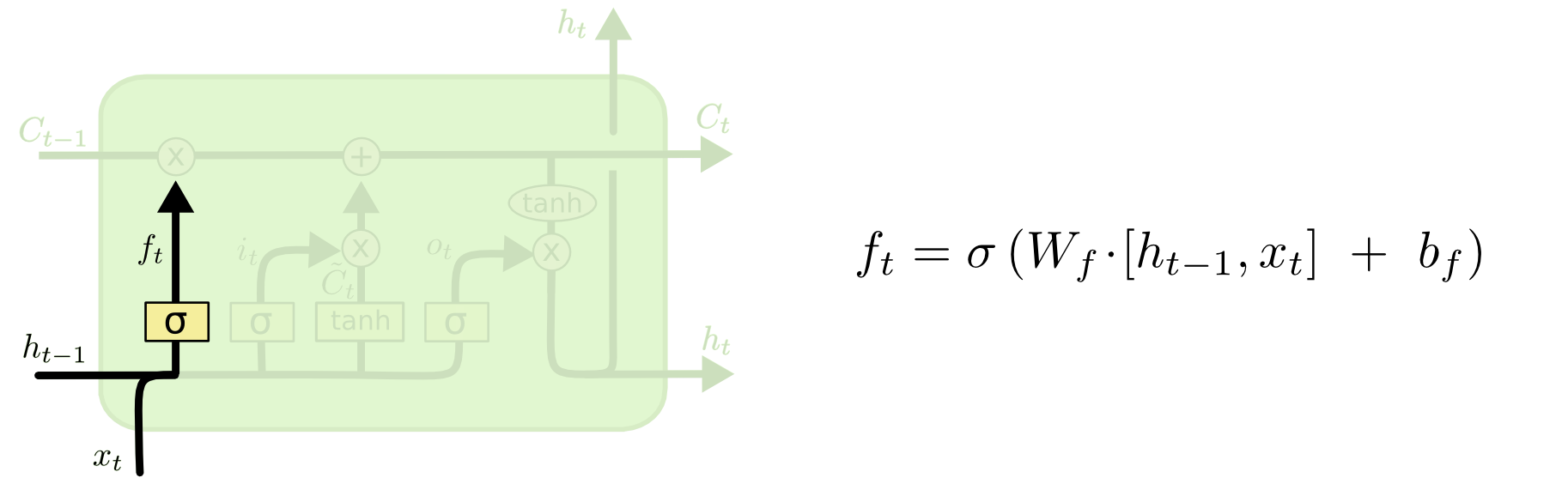
- 과거 시점의 기억(
C_{t-1})을 얼마나 다음 시점으로 가져갈지를 정하게 되는 게이트이다. - sigmoid 함수를 거쳐 (0, 1)의 값을 갖게 되는데,
C_{t-1}의 벡터값과 곱함으로써 0에 가까운 값과 곱해진 벡터값(기억)은 많이 소실되고, 1에 가까운 값과 곱해진 기억은 보존이 되는 형태이다. - 즉 과거의 기억을 Short term으로 가져갈지, Long term으로 가져갈지를 일관된 규칙에 따라 선택하게 된다.
3. Candidate + Input gate
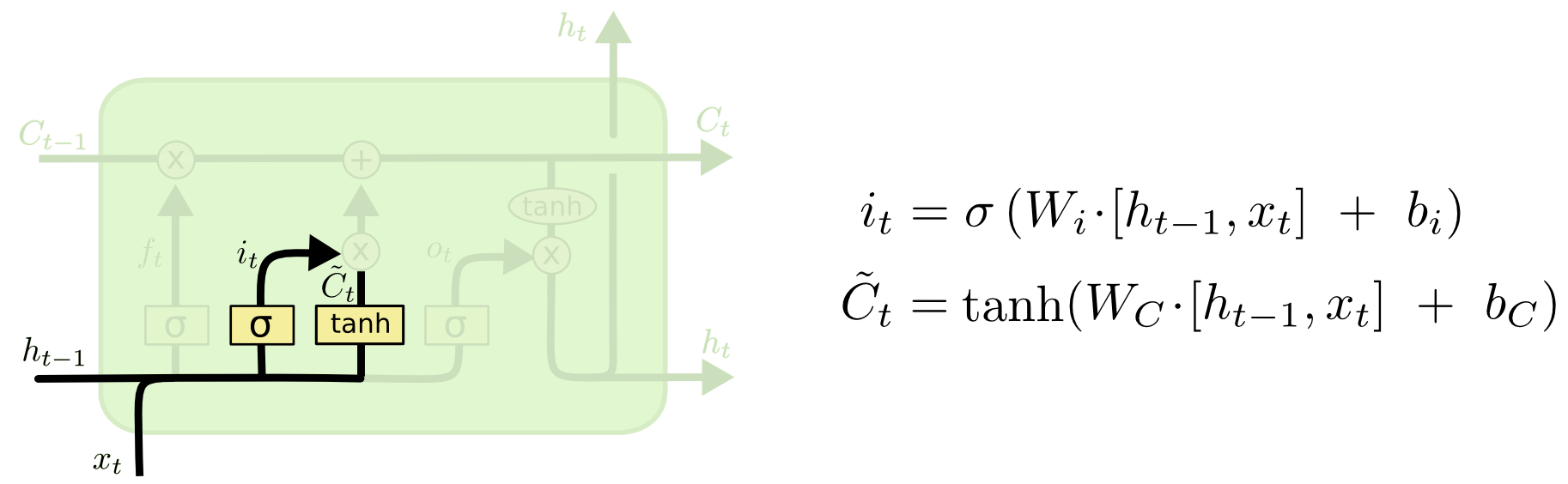
~C_{t}(C tiled) : 현재 시점의 기억 후보(memory candidate)를 뜻한다.i_{t}: C tiled에 대해 forget gate와 동일한 역할을 한다. 기억 후보의 벡터 값을 얼마나 다음 기억에 반영할 지 (0, 1) 범위의 값과 곱함으로써 결정한다.
4. Update Cell state
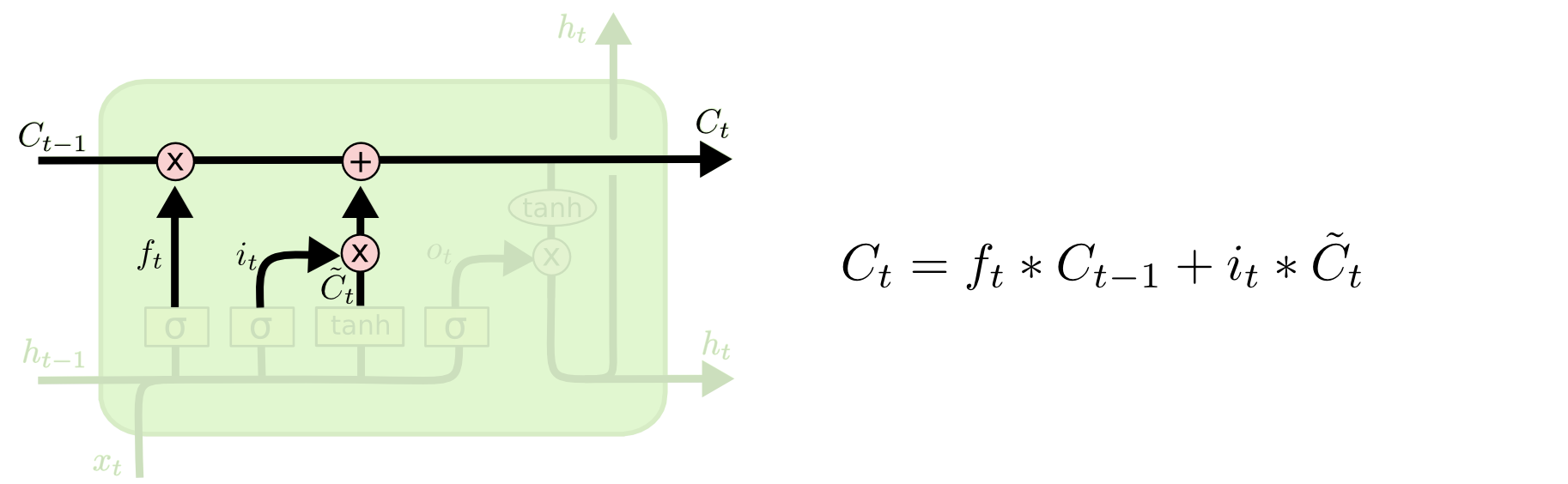
0 ~ t-1 시점의 기억에 t 시점의 기억을 더하여 0 ~ t 시점의 기억을 생성하는 과정이다.
- LSTM은 모든 시점에 일관된 규칙을 적용한다는 RNN 구조를 그대로 유지하고 있다.
- 즉 더해지는 벡터값들은 모두 동일한(혹은 유사한) Feature를 나타내고 있기 때문에 덧셈 연산을 하여도 기존의 Feature를 유지할 수 있다.
5. New Hidden State (Output gate)
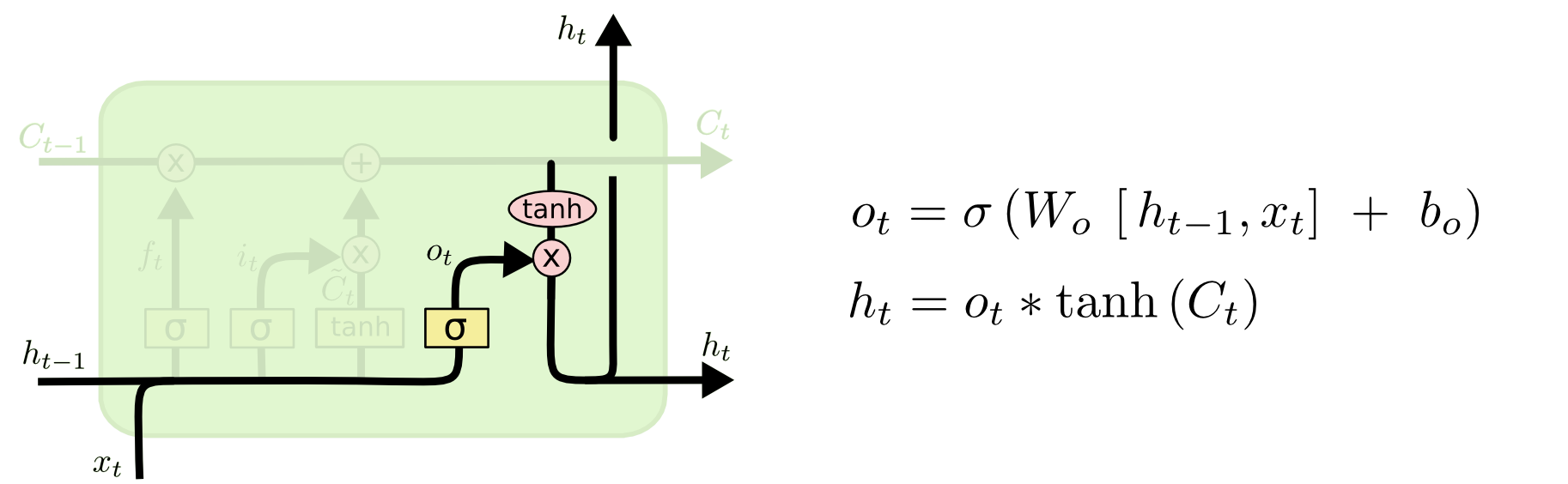
Update Cell state에서 생성된 현재 시점의 기억 정보를 tanh 함수를 통해 -1 ~ 1로 정규화 한다.
여기에 또다른 sigmoid 게이트인 output gate(
o_{t})로 정규화된 기억정보의 각 특징을 얼마나 반영할지 결정한다.이를 통해 현재 시점 t의 Hidden state를 생성한다.
LSTM의 파라미터
- RNN에서는 한번만 수행했던
h_(t-1)과x_{t}사이의 가중치 업데이트를 총 4번 수행한다.- Forget gate (activation=sigmoid)
- Input gate (activation=sigmoid)
- C tiled (activation=tanh)
- Output gate (activation=sigmoid)
- 즉 LSTM의 파라미터는 RNN의 4배이다.
LSTM 모델링
- RNN처럼 Tensorflow keras에서 제공하는 LSTM 레이어를 사용한다.
- 기본 구조가 RNN과 동일하므로, SimpleRNN과 동일한 문법을 사용한다.
- gate에 사용할 활성함수와, 특징 추출(C tiled)에 사용할 활성함수를 각각 선택할 수 있다는 차이점이 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
LSTM_1 (LSTM) (None, 21, 16) 1152
LSTM_2 (LSTM) (None, 21, 32) 6272
flatten (Flatten) (None, 672) 0
dense (Dense) (None, 1) 673
=================================================================
Total params: 8,097
Trainable params: 8,097
Non-trainable params: 0
_________________________________________________________________
- 위의 RNN 모델과 비교했을 때 파라미터가 4배임을 확인할 수 있다.
- 또한 Cell State를 저장할 공간이 추가로 필요하다.
- 그만큼 무거운 모델이지만, RNN보다 시계열 데이터에 대해 좋은 성능을 보인다.
GRU
figure : colah - Understanding LSTM Networks

- LSTM의 Cell state, Hidden state 두 가지로 나누어진 것을 Hidden state하나로 합침으로써 연산량(파라미터)를 줄인 모델이다.
- 필요한 연산이 3개로, 완벽하게 나누어떨어지지는 않지만 LSTM의 약 3/4배의 파라미터를 갖는다.
1. Reset Gate
- LSTM의 Forget Gate와 같이 과거 시점의 정보를 적당히 리셋하여 정보의 보존 및 손실 정도를 결정한다.
- Sigmoid를 통해 (0, 1)의 값을 곱해줌으로써 처리한다.
- Reset Gate를 거쳐 정돈된 과거 시점 Hidden state는 현재 시점의 Hidden state를 추출하는 것에 사용한다.
2. Update Gate
- 현재의 Input정보와 과거 시점의 정보를 어느정도의 비율로 반영할지 결정한다.
- Sigmoid를 통해 출력된 값(
z_{t})이 현재 시점의 정보를 반영하는 게이트로 사용되며, 반대로1-z_{t}값이 과거시점의 정보를 반영하는 게이트로 사용된다. - 완벽히 일치하지는 않지만, LSTM의 Forget gate와 Inpurt gate를 역할을 동시에 수행하는 것과 유사하다.
3. Candidate + Update hidden state
LSTM에서는
h_{t-1}와x_{t}를 그대로 사용하여 현재 시점 정보의 후보(candidate)를 생성하였지만, GRU에는 Reset Gate를 한번 거쳐 정돈된h_{t-1}을 사용한다.생성된 후보는 tanh와 Update Gate를 거쳐 LSTM과 동일한 과정으로 새로운 Hidden state가 된다.