Aivle Til 230403 4차 미니프로젝트 1일차
Aivle Til 230403 4차 미니프로젝트 1일차
title: AIVLE TIL (‘23.04.03) 4차 미니프로젝트 1일차 date: 2023-04-03 12:40:12.115 +0000 categories: [에이블스쿨] tags: [‘aivle’] description: 데이터 탐색 및 전처리 (토큰화) image: /assets/posts/2023-04-03-aivle-til-230403-4차-미니프로젝트-1일차/thumbnail.png
참고 절차
- 구글 머신러닝 텍스트 분류 가이드
- 에이블스쿨 강의 교안
프로젝트 주제
메인 과제
- 에이블스쿨과 관련된 텍스트 데이터의 유형을 분류하는 문제이다.
- 아마 이미 한 차례 가공이 되었겠지만, 정말 실무에서 사용할 법한 과제와 데이터셋이 주어져서 인상 깊었다.
- 프로젝트는 총 5일에 걸쳐 진행되며, 1~4일은 각각 전처리 및 모델링을 진행하고, 마지막 5일차에 Kaggle Competition을 진행한다.
무엇을 했나?
데이터 탐색
1. 데이터 확인
- 라벨 클래스의 분포를 확인하고, 라벨링이 잘 되어있는지 무작위로 샘플링하여 직접 확인
- DataFrame이라면, 판다스 함수를 이용하여 데이터 타입과 결측치 등을 확인한다.
2. 주요 측정항목 확인
- 데이터의 특성을 파악하고, 적절히 처리하는 방법을 도출하기 위해 몇가지 주요항목을 측정한다.
- 샘플 수
- 데이터가 많다면 좋지만, 데이터가 적을 경우 딥러닝 보다는 규칙기반의 머신러닝이 오히려 좋은 성능을 보일 때도 있기 때문에 샘플의 수를 파악해서 적절히 선택해야한다.
- 클래스 수
- 클래스 당 샘플 수
- 불균형 데이터 파악
- 샘플 당 단어 수
- 구글 가이드에서는 중앙값을 기준으로 한다.
- 단어의 빈도 분포
- 어떤 단어가 많이 분포되어있는지 확인한다. 특히 토큰화 후 별다른 처리 없는 코퍼스의 빈도 분포를 그려보면 왜 불용어 처리가 중요한지 알 수 있다.
- 샘플 길이 분포
- 한 샘플에 몇개 단어가 들어있는지의 분포
예시
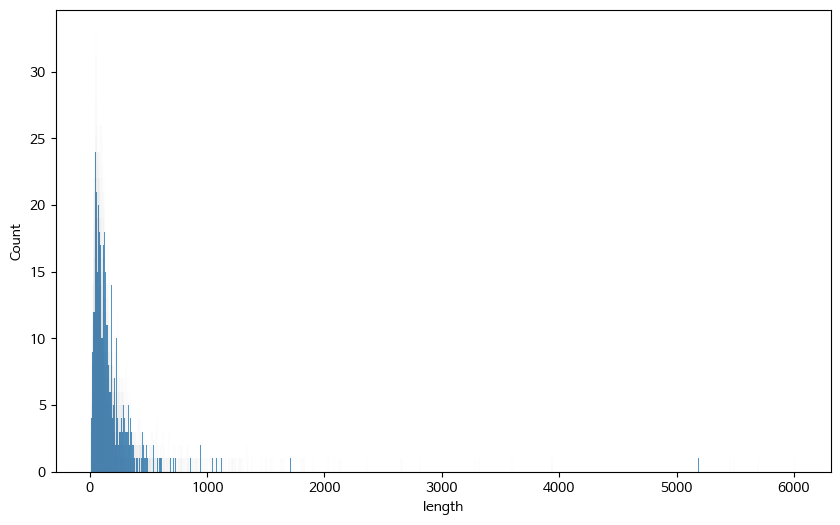
- 샘플의 길이 분포이다. 토큰화하지 않고 순수하게 문서의 텍스트 길이를 기준으로 분포를 그렸다.
- 대부분의 문서 길이가 500 이내인 것에 반해 일부 문서의 최대치가 6000이 넘는다.
- 만약 이대로 딥러닝 모델에 집어넣으려면 대부분의 문서가 PAD로 가득차게 될 것이므로 적절한 truncating 또는 drop이 필요해 보인다.
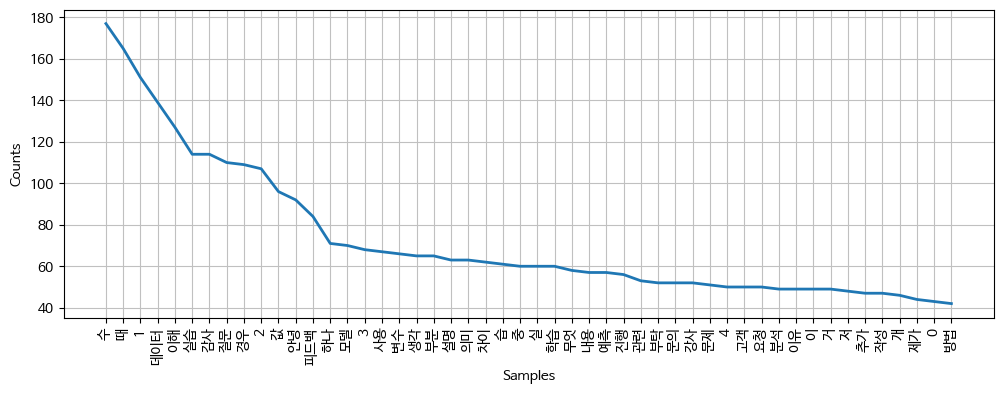
- 단어 중에서 명사만 추출하여 빈도 분포를 그린 결과이다.
- ‘수’, ‘때’는 사실
할 '수' 있다,~할 '때'처럼 명사로 쓰인것이 아니지만 명사로 분류되었고, 가장 높은 빈도를 보인다. 하지만 이는 자연어 처리시 전혀 중요한 데이터가 아니기 때문에 실제 분석시는 불용어로 처리하거나 TD-IDF와 같은 기법을 사용해서 낮은 중요도로 판단하도록 하는 처리 등이 필요해보인다.
3. 문법 교정하기
교안에는 없지만, 추후 분석시 더 좋은 모델 성능을 얻고자 문법을 교정하는 처리를 추가하였다
- 이러한 처리를 추가한 이유는 형태소 분석기로 kkma를 사용할 것인데, kkma는 띄어쓰기가 되어있지 않은 문장을 처리할 때 성능이 크게 감소하기 때문이다.
- 또한 오타 등으로 인해 단어가 잘 분류되지 않는 것을 최대한 줄여보고자 하였다.
교정 전 : 현재 이미지를 여러개 업로드 하기 위해 자바스크립트로 동적으로 폼 여러개 생성하는데... 교정 후 : 현재 이미지를 여러 개 올리기 위해 자바스크립트로 동적으로 폼 여러 개 생성하는데 ...
- 문법 교정에는 나라인포테크의 맞춤법 검사기를 사용하였다. (데이터 수가 작아서 가능했는데, 데이터 수가 조금만 많아져도 처리에 엄청 시간이 소요된다)
- 여러개 -> 여러 개로 띄어쓰기 된것을 확인할 수 있다. 또한
업로드 하기와 같은 외래어 조합이올리기로 변환되었다.
4. 명사 추출 및 품사 태깅
- Kkma외에 Okt, Mecab과 시간을 비교해보았다.
- Mecab(7.12s) < Okt(1min 19s) < Kkma (8min 17s)
- Kkma가 제일 오래 걸리는 것을 확인할 수 있다, 만약 속도가 중요한 경우라면 처리속도가 매우 빠르면서 준수한 성능을 보이는 Mecab으로 형태소 분석을 하는 것이 좋을 것 같다.
워드 클라우드
[WordCloud for Python documentation] (https://amueller.github.io/word_cloud/)
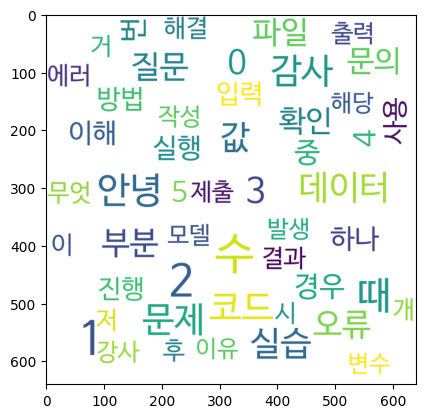
- 파이썬에서 워드 클라우드를 쉽게 생성할 수 있게해주는 라이브러리이다.
cloud.to_file()메소드를 통해 이미지 형태로 저장도 가능하다.
기타 분석
Collocation
- Collocation(연어) : 연속하여 등장하는 언어쌍라는 뜻으로, 통계 기반의 자연어 처리에서 사용하던 지표이다.
공을 차다는공을 먹다,공을 하다보다 훨씬 더 많이 연속하여 등장할 것이다. 이렇게 연속적으로 등장하는 빈도수를 통해 밀접한 관계가 있는 언어쌍을 추출할 수 있다.- nltk가 제공하는
concordance()와similar()메소드를 통해 쉽게 확인할 수 있다.
샘플수(S) / 샘플당 단어 수(W) 비율
- 구글 가이드에서 설명하는 지표로, 이 지표가 1500 미만일 경우 시퀀스 모델보다 적은 층을 가진 다층 퍼셉트론(MLP)이 일반적으로 더 좋은 성능을 낸다고 한다.
- 연산에 필요한 시간도 적어지므로 구글 가이드에서는 이러한 경우 MLP를 사용할 것을 권장한다.
- 이번 프로젝트에 사용할 데이터셋도 S/W 비율이 약 50정도로 딥한 시퀀스 모델보다는 MLP를 사용하는 것이 좋을 것 같다.
함수화
- 위의 과정을 하나의 함수안에 담아보았다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
def text_analysis(df, label=None, plot_num=50, counter_num=50):
# 데이터 확인
print('-' * 100)
print('분석할 label:', label)
print(data.head())
print('데이터 정보\n',data.info())
print('결측치 숫자\n',data.isnull().sum())
# 데이터 길이 시각화
print('-' * 100)
length = data['cor_text'].apply(len)
plt.figure(figsize=(10, 6))
sns.histplot(x=length, binwidth=1, cumulative=False)
plt.title('Distribution of data length')
plt.show()
# 명사 추출하여 분석
tokenizer = Kkma()
# kkma 형태소 분석기의 명사 토큰화 결과를 저장
nouns = []
for doc in data['cor_text']:
noun = tokenizer.nouns(doc)
nouns.append(noun)
nouns = [sum(nouns, [])]
# 리스트 -> nltk.Text
nltk_text = nltk.Text(*nouns)
# nltk.Text -> FreqDist
dist = FreqDist(nltk_text)
# Num of samples / Nom of words per samples
print(len(data['cor_text']) / length.mean())
# Type-Token Ratio 출력
print('-' * 100)
print('Type-Token Ratio:', np.round(dist.B() / dist.N(), 3))
# 단어 분포 시각화
print('-' * 100)
plt.figure(figsize=(12, 4))
dist.plot(plot_num, cumulative=False)
plt.show()
# Collocation 확인
print('-' * 100)
nltk_text.concordance(label)
print('-' * 100)
nltk_text.similar(label)
# 워드클라우드 분석 및 시각화
counter = Counter(nltk_text)
counts = counter.most_common(counter_num)
# 워드 클라우드 생성
wc = WordCloud(font_path='NanumBarunGothic.otf',
background_color="white",
max_font_size=80,
width=640,
height=640)
cloud = wc.generate_from_frequencies(dict(counts))
# 시각화 출력
plt.imshow(cloud)
plt.show()
# 저장
cloud.to_file('wordcloud.jpg')
코멘트
다음번에 더 개선해 볼만 한 것
전체 텍스트 데이터에 대해서만 길이 분포를 확인했었는데, 각 클래스별 길이분포를 구해보는 것도 좋을 것 같다. (subplot을 활용해보자)
결측치 확인 및 전체적인 분포 확인에는 ydata-profiling을 이용하는 것이 효율적일 수도 있을 것 같다.
This post is licensed under CC BY 4.0 by the author.