Aivle Til 230405 4차 미니프로젝트 4일차
title: AIVLE TIL (‘23.04.05) 4차 미니프로젝트 4일차 date: 2023-04-06 15:44:35.214 +0000 categories: [에이블스쿨] tags: [‘aivle’] description: 믿을건 남들이 만든 모델 뿐이야!!! image: /assets/posts/2023-04-06-aivle-til-230405-4차-미니프로젝트-4일차/thumbnail.png
Pre-trained Model
- 아쉬웠던 딥러닝 모델의 성과는 뒤로 하고, 허깅페이스의 pre-trained model을 가져와 fine-tuning을 통해 문제를 풀어보기로 하였다.
koAlpaca
- 먼저 Alpaca는 얼마전 유출된 메타의 LLaMA모델을 바탕으로 Instruction-Following 데이터로 Aligning된 모델이다. 쉽게 말하면 사용자의 명령에 잘 답하도록 튜닝된 모델이다.
- koAlpaca는 Alpaca에 한국어를 학습시킨 모델이다.
- Instruction만 일관성있게 잘 제시하고, input으로 학습 데이터의 text를, output으로 label을 출력하게 하면 분류문제도 풀 수 있지 않을까? 싶어 학습을 시도해보았다.
스크립트를 통한 학습 시도
- 처음에는 koAlpaca 모델을 배포하신 Beomi님의 깃허브를 클론하여 참고해가면서 더듬더듬 코드를 작성했다.
- train.sh 스크립트 파일에 학습 데이터(json)나 학습 관련 설정, 하이퍼파라미터 등을 지정하여 리눅스 sh 명령어를 통해 train.py를 실행하는 것이었다.
json 라이브러리를 이용하여 학습 데이터를 instuction, input, label로 나누었고, 대충 파라미터를 나누어 학습을 진행했다.
- 그러나 cuda 설정 관련 에러 등 무수히 많은 에러를 맞이 했고, 이것저것 막아보려 시도했지만 제대로 된 지식 없이 고칠만한 것이 아니라 생각하여 다른 방법을 찾게 되었다.
Trainer를 통한 학습 시도
- 허깅페이스가 제공하는 튜토리얼을 통해 Trainer class를 통한 학습을 시도하였다.
- Trainer class 덕분에 PyTorch 문법을 몰라도 API를 사용하듯이 모델의 Fine tuning이 가능하다. 물론 쓰면 쓸 수록 PyTorch 문법을 배워야겠다는 생각이 강하게 들었다…
Dataset 제작
- PyTorch 모델에 데이터를 넣기 위해서는 Pyarrow Dataset으로 만들어 주어야 한다.
- 이 부분은 튜토리얼에도 잘 나와있지 않아 좀 해멨지만, 이전에 koGPT 경진대회에 참여했을 때 Dataset으로 고생한 적이 있었기에 다행히 막히지는 않았다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 학습 및 테스트 데이터 불러오기
df_train = pd.read_csv(ROOT+'train_split.csv', encoding='utf-8')
df_test = pd.read_csv(ROOT+'test_split.csv', encoding='utf-8')
# DataFrame -> Dataset
train_set = datasets.Dataset.from_pandas(df_train)
test_set = datasets.Dataset.from_pandas(df_test)
# 토큰화 함수 정의
def train_batch_preprocess(batch):
return tokenizer(batch['cor_text'], padding='longest', truncation=True)
# map 메소드를 이용한 토큰화 (cor_text는 더이상 필요 없으므로 제거)
tk_train_set = train_set.map(train_batch_preprocess,
batched=True,
remove_columns=['cor_text'])
tk_test_set = test_set.map(train_batch_preprocess,
batched=True,
remove_columns=['cor_text'])
# 결과 확인
df_temp = pd.DataFrame(tk_train_set)
df_temp.head(2)

학습 파라미터 설정 및 학습
- 사실 이때쯤부터 어? 이거 텍스트 생성 모델인데 분류 문제처럼 label을 줘도 되나? 라는 생각을 했었다.
- 그냥 시도나 해보자는 생각으로 튜토리얼을 따라 학습 파라미터를 설정하고 학습을 진행했다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
from transformers import TrainingArguments, Trainer
import evaluate
params = {
'output_dir' : 'test_trainer',
'num_train_epochs' : 3,
'per_device_train_batch_size' : 4,
'per_device_eval_batch_size' : 4,
'gradient_accumulation_steps' : 8,
'evaluation_strategy' : 'no',
'save_strategy' : 'steps',
'save_steps' : 1000,
'save_total_limit' : 1,
'learning_rate' : 2e-5,
'warmup_ratio' : 0.03,
'lr_scheduler_type' : 'cosine',
'logging_steps' : 1,
}
training_args = TrainingArguments(**params)
metric = evaluate.load("accuracy")
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tk_train_set,
eval_dataset=tk_test_set,
compute_metrics=metric,
)
trainer.train()

펑!
- 40GB VRAM을 가진 코랩 프로 GPU를 이용했음에도 out of memory가 발생하였다.

- Github를 찾아보니 base 모델을 만들 때에도 80GB의 VRAM을 가진 GPU를 사용했다고 한다.
- koGPT 모델을 사용할때 LoRA 학습을 통해 컴퓨팅 자원을 덜 소모하는 방법이 있었는데, 분류 문제에 적용하는 방법을 찾지 못하였다.
- 결국 koAlpaca는 여기서 놓아주기로 하였다.
KR-FinBert-SC
허깅페이스에서 Korean + Text Classification으로 검색한 모델 중, 한국어 전문 모델이면서 가장 다운로드 수가 많은 모델을 사용하였다.
다른 과정은 koAlpaca때와 동일하지만, 분류 클래스 수가 다르므로, 모델을 불러올 때
num_labels를 지정해야한다.
1
2
3
4
5
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("snunlp/KR-FinBert-SC")
model = AutoModelForSequenceClassification.from_pretrained("snunlp/KR-FinBert-SC", num_labels=5, ignore_mismatched_sizes=True)
1차시도
KR-FinBert is trained for 5.5M steps with the maxlen of 512, training batch size of 32, and learning rate of 5e-5, taking 67.48 hours to train the model using NVIDIA TITAN XP.
- 모델 카드의 적힌 내용에 따라 batch size, learning rate, maxlen을 동일하게 지정하였다.
- 그 외에 learning_rate_scheduler를 적용하였는데, cosine with warmup을 지정하였다.
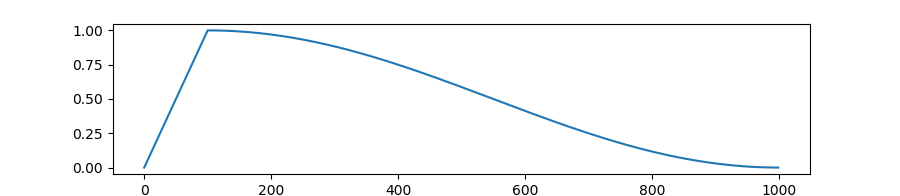
- 러닝레이트가 이런식으로 상승한다. 지정한 warmup ratio만큼 학습률이 상승하다가, 코사인 곡선 형태로 감소한다.
결과
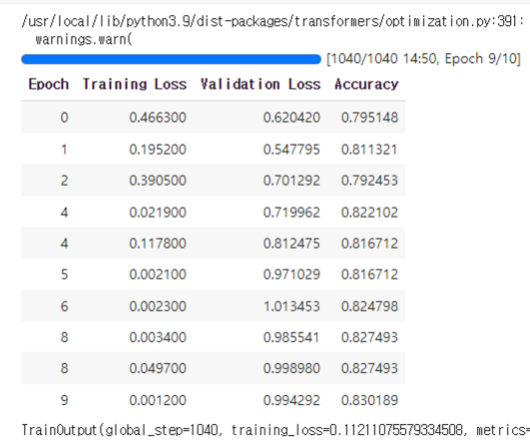
- AutoML을 돌렸을 때의 최대 Accuracy가 0.8342였는데 여기에 근사하는 수치를 보였다.
- Validation Loss는 증가했는데 Accuracy도 덩달아 증가한 점이 흥미롭다 (노이즈 때문일까?)
다음 학습
- 우선 3epoch만에 Val_Loss가 증가하기 시작했으므로 Learning Rate를 낮추기로 하였다.
- 또한 형태소 분석기로 토큰화 및 시퀀스 데이터화 했을 때 토큰 길이를 약 200으로 맞추었던 것이 떠올라 maxlen도 200으로 조정하였다.
- 또한 kaggle 지표로 사용될 것이 유력한 f1-macro를 metric으로 지정하였다.
- 그 외에는 epoch를 조금 넉넉히 주고
EarlyStoppingCallback을 적용하였다.
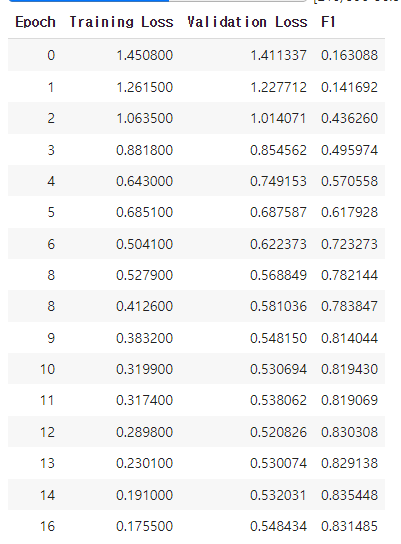
- 16epoch에서 학습이 종료되었는데, val_loss가 0.520826으로 꽤 감소한 것을 확인할 수 있었다.
- F1-Score는 역시 AutoML과 유사한 score를 기록했다.
xlm-roberta-base-multilingual-text-genre-classifier
- 한국어 외 다양한 멀티 언어를 학습한 조금 더 큰 모델이다.
- 조금 더 큰 모델이고, 학습 내용중에는 코드도 있기 때문에 혹시 영어도 학습한 모델이라면 코드를 조금 더 잘 학습할 까 싶어 가져와보았다.
- 학습 조건은 KR-FinBert-SC에서 가장 좋은 성능을 보인 것과 동일한 조건을 사용하였다.
1
2
3
4
5
6
7
8
9
10
11
precision recall f1-score support
0 0.89 0.85 0.87 159
1 0.81 0.84 0.82 73
2 0.77 0.79 0.78 73
3 0.83 0.86 0.84 56
4 0.91 1.00 0.95 10
accuracy 0.84 371
macro avg 0.84 0.87 0.85 371
weighted avg 0.84 0.84 0.84 371
- loss도 적고, f1-macro score가 0.85를 달성했다.
- 항상 0번과 3번 class의 낮은 f1-score가 골치였는데, 0번(코드)에 대한 성능이 유의하게 증가한 것 같아 다행이다.
- 다만 한국어로만 이루어진 나머지 클래스 (1, 2, 3)에 대해서는 머신러닝보다 조금 더 낮은 성능을 보였다.
소감
삽질에 삽질을 거듭했던 하루였다. 그래도 괜찮은 모델과 학습 파라미터를 찾았으니 kaggle에서 해야할 일의 방향성을 명확히 잡은 것 같다.
그리고 다른 시도들도 해보고 싶은 것이 많았는데, Torch 문법의 벽에 가로막혀 하지 못한 것들이 많다.. 오류 때문에 시간도 많이 까먹게 되었는데, 꼭 Torch 문법도 공부해야겠다.