Aivle Til 230407 4차 미니프로젝트 5일차
Aivle Til 230407 4차 미니프로젝트 5일차
title: AIVLE TIL (‘23.04.07) 4차 미니프로젝트 5일차 date: 2023-04-07 12:19:32.549 +0000 categories: [에이블스쿨] tags: [‘aivle’] description: Kaggle Competition image: /assets/posts/2023-04-07-aivle-til-230407-4차-미니프로젝트-5일차/thumbnail.png
Kaggle Competition
- 2번째 Kaggle Competition이 돌아왔다.
이번 주제는 지난 4일간 했던 Text Classification의 연장으로, 기존에 사용했던 데이터를 통째로 학습 데이터로 사용한다. 그리고 캐글에 주어진 데이터의 label을 예측하여 F1-macro score로 모델의 성능 경쟁을 진행하였다.
- 지난 4일동안 데이터 전처리 및 분석을 하면서 정리한 결과는 다음과 같다.
- 맞춤법 검사기를 이용해 텍스트 데이터를 한번 정제하면 성능이 상승한다.
- 머신러닝 모델중에서는 SVM, Ridge Classifier, Logistic Regression의 성능이 뛰어났다.
- (직접 모델링한) RNN 기반 딥러닝 모델은 성능이 좋지않다.
- 한국어 데이터셋을 학습한 pretrained-model의 성능도 시도해볼 가치가 있다.
- 결과적으로 이번 경진대회에서의 전략은 다음과 같았다.
- 최종 학습 시에는 반드시 학습 데이터 전체에 대해 학습 (기존에는 검증용 데이터를 쪼갠 상태로 학습한 경우가 많았다)
- 머신러닝은 가장 성능이 좋았던 Ridge Classifier로 모델링
- 기존 데이터에서 가장 성능이 좋았던 pretrained-model 하나를 정하여 모델링
- 학습 결과를 분석하여 모델에서 어떤 클래스를 잘 예측하지 못했는지 확인하고, 적절히 보완
- 조금이라도 도움이 될만한 코드들은 팀원과 적극 공유한다.
코드 리뷰 (총정리)
문법 교정
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
## 문법 교정 적용
for idx, row in test_df.iterrows():
text = row['text']
response = requests.post('http://164.125.7.61/speller/results', data={'text1': text})
# 응답에서 필요한 내용 추출 (html 파싱)
html = response.text.split('data = [', 1)[-1].rsplit('];', 1)[0]
# json_text를 dictionary로 변환
output_text = text
try:
json_dict = json.loads(html)
# 교정된 문장 추출
for info in json_dict['errInfo']:
output_text = output_text.replace(info['orgStr'], info['candWord'].split('|')[0])
except:
pass
test_df.loc[idx, 'cor_text'] = output_text
- 다소 무식한 방법으로, 나라인포테크의 맞춤법 검사기에 직접 텍스트를 쏘고 응답을 받아오는 방식으로 하였다.
- 데이터 수가 많지 않음에도 1시간 가량이 소요되는 방법이다.
다만 나라인포테크의 맞춤법 검사가 정확도 높기로 유명하기 때문에, 가장 확실한 방법인 것 같다.
처리 결과로는 띄어쓰기의 올바른 교정이 대부분이었고, 일부
업로드하다->올리다와 같은 외래어 및 외국어나 간단한 오타 교정이 있었다.- 다른 조의 발표를 듣고 알게된 사실인데, 네이버가 제공하는 py-hanspell이라는 한국어 맞춤법 교정 라이브러리가 있었다. 다음부터는 이쪽을 사용하기로 하였다.
텍스트 전처리
정규식을 통한 특수문자 제거
1
2
3
4
5
6
7
8
9
# 정규식 라이브러리 불러오기
import re
# 숫자, 알파벳, 한글이 아닌 모든 문자를 띄어쓰기로 변환 + 코드에서 자주 사용되는 소괄호와 대괄호를 남김
def stopwords(text):
return re.sub('[^0-9a-zA-Zㄱ-ㅣ가-힣()\[\]]', ' ' ,text)
x_train = x_train.apply(stopwords)
x_val = x_val.apply(stopwords)
- 특수문자를 모두 지우는 정규식을 적용하였다.
- 예외적으로 소괄호, 대괄호를 남겼는데, 코드에서 많이 사용되는 만큼 코드 구분에 유용하지 않을까라는 생각이었다.
TF-IDF matrix
1
2
3
4
5
6
7
8
9
10
# Countvectorizer 및 Kkma 토크나이저 불러오기
from sklearn.feature_extraction.text import TfidfVectorizer
from konlpy.tag import Kkma
# vectorizer 선언 (unigram)
tokenizer = Kkma()
vectorizer = TfidfVectorizer(tokenizer=tokenizer.morphs, ngram_range=(1, 1))
# 벡터화
x_train_uni = vectorizer.fit_transform(x_train)
x_val_uni = vectorizer.transform(x_val)
띄어쓰기가 올바르게 처리되었다고 생각하여, konlpy가 제공하는 것중 가장 좋은 성능을 보인다고 알려진 꼬꼬마 형태소 분석기를 사용하였다.
이것도 다른 조의 발표를 듣고 알게된 사실인데, 현재는 바른 형태소 분석기의 성능이 제일 우수하다고 한다. 별도로 설치하여 사용할 수 있다.
머신러닝 모델링
- SVM과 Ridge Classifier의 하이퍼파라미터 튜닝을 하였고, 그 중 더 높은 성능을 보였던 Ridge Classifier를 최종 선정하였다.
- 하이퍼파라미터 튜닝에는 베이지안 최적화를 이용하였다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
from skopt import BayesSearchCV
from skopt.space import Real, Integer, Categorical
# 베이지안 최적화
model_svm = SVC()
params = {
'kernel' : Categorical(['sigmoid', 'linear']),
'C' : Real(1, 50, prior='log-uniform', base=2),
'gamma' : Real(0.1, 10, prior='log-uniform', base=2),
}
result_svm = BayesSearchCV(model_svm, params, scoring='f1_macro', n_jobs=-1, cv=5, verbose=1, n_iter=30)
# 학습
result_svm.fit(x_train_uni, y_train_reset)
# 결과 확인
print(result_svm.best_params_)
print(result_svm.best_score_)
# 테스트 결과 상위 순 정렬
columns =['param_C','param_gamma','param_kernel','mean_test_score','std_test_score','rank_test_score']
result_df = pd.DataFrame(result_svm.cv_results_)
result_df.sort_values('rank_test_score', ignore_index=True).loc[:10, columns]
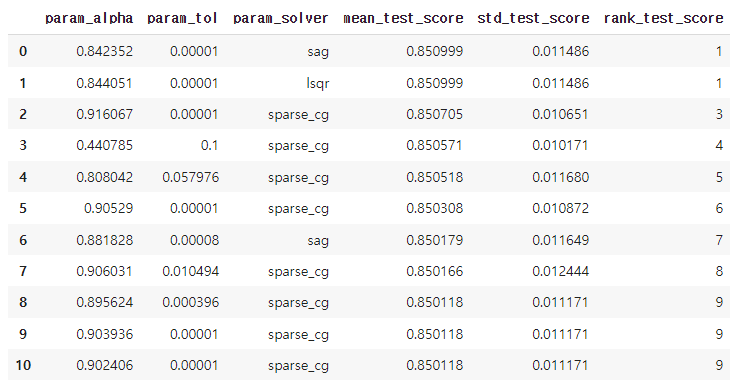
- 테스트 결과를 상위순으로 정렬하고, 범위를 좁혀 다시 베이지안 최적화를 진행하는 것을 반복하였다.
- 범위가 어느정도 좁아진다면 GridSearch를 진행하는게 더 효율이 좋을 것 같다. 베이지안 최적화는 범위에 상관없이 n_iter값에 따라 일정한 시간이 걸리기 때문이다.
1
2
3
4
5
6
7
8
9
10
11
12
F1-score 0.8691529724689302
precision recall f1-score support
0 0.91 0.88 0.89 159
1 0.94 0.86 0.90 73
2 0.74 0.88 0.80 73
3 0.93 0.89 0.91 56
4 0.89 0.80 0.84 10
accuracy 0.88 371
macro avg 0.88 0.86 0.87 371
weighted avg 0.88 0.88 0.88 371
- 하이퍼파라미터 튜닝 결과 검증용 데이터에 대해 0.87의 높은 F1-macro score를 기록하여 전체 데이터로 학습한 뒤 제출하였다.

- 조원분이 딥러닝을 통해 0.85678을 기록한 것이 최고기록이었고, Ridge Classifier는 근소한 차이로 두번째였다.
- 이 결과를 구했을 때가 오전 10시경이었는데, 이게 사실상 최고점수가 될줄은 몰랐다.
Fine-Tuning
- 미리 골라두었던 KR-FinBert-SC를 가져와 PyTorch Trainer를 이용해 학습하였다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
from transformers import AutoTokenizer, AutoModelForSequenceClassification
from transformers import Trainer, TrainingArguments
# 토크나이저 및 모델 불러오기
tokenizer = AutoTokenizer.from_pretrained("snunlp/KR-FinBert-SC")
model = AutoModelForSequenceClassification.from_pretrained("snunlp/KR-FinBert-SC", num_labels=5, ignore_mismatched_sizes=True)
# Dataset 생성
def train_batch_preprocess(batch):
return tokenizer(batch['cor_text'], padding='max_length', truncation=True, max_length=200)
tk_train_set = train_set.map(train_batch_preprocess,
batched=True,
remove_columns=['cor_text'])
tk_test_set = test_set.map(train_batch_preprocess,
batched=True,
remove_columns=['cor_text'])
# 학습 조건 지정
params = {
'output_dir' : 'test_trainer',
'num_train_epochs' : 9,
'per_device_train_batch_size' : 8,
'per_device_eval_batch_size' : 8,
'gradient_accumulation_steps' : 8,
'save_strategy' : 'epoch',
'save_total_limit' : 1,
'learning_rate' : 1e-5,
'warmup_ratio' : 0.03,
'lr_scheduler_type' : 'cosine',
'logging_steps' : 1,
}
training_args = TrainingArguments(**params)
# 학습
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tk_train_set,
)

- 성능은 실망스러웠고, 이후에도 다른 bert 모델을 불러오거나, 다른 머신러닝 모델 학습을 시도하였지만, 제출한 답과 비교해봤을 때 오답이 많을 것이라 생각이 들어 제출하지 못하였다.
보팅
- 모델의 예측 분석을 위해 서로 다른 모델을 통해 예측한 정답을 비교해보았다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 서로 다른 데이터 확인
diff = []
for i, label in enumerate(my):
if other[i] != label:
diff.append((i, my[i], other[i]))
# 레이블 딕셔너리 설정
label_dict = {
0 : '코드',
1 : '웹',
2 : '이론',
3 : '시스템 운영',
4 : '원격'
}
for i, pred, pred_cor in diff:
print('-'*50)
print('ID :', i)
print('나의 예측 :', label_dict[pred])
print('영재님 예측 :', label_dict[pred_cor])
print('내용 :', test_df.loc[i, 'text'])

- 머신러닝 모델은 대체로
코딩을 많이 예측하는 경향이 있었고, 딥러닝 모델은 대체로시스템 운영,이론을 많이 예측하는 경향이 있었다. - 두 예측값의 점수는 0.001도 차이나지 않는 수준이었는데 전체 900여개의 테스트 데이터중 무려 103개나서로 다르게 예측한 것으로 나와 두 모델에서 좋은 답안만 합치면 성능이 크게 오르지 않을까? 라는 생각을 하였다.
그 결과 보팅이라는 아이디어가 떠올랐다.
- 예측 2개로 보팅을 할순 없기에 예측결과가 0.8이상이 나온 머신러닝 기반 모델 3개와 딥러닝 기반 모델 3개의 예측값 중 더 많이 예측된 것을 최종 예측값으로 정하였다.
1
2
3
voted_df = pd.DataFrame({
'voted': df_merged.apply(lambda x: x.value_counts().index[0], axis=1)
})
- 원래는 홀수개로 하는 것이 맞다고 생각하였으나 6개로 보팅을 한 것이 가장 성능이 우수했다.
- 가능하면 각 모델의 성능점수만큼 가중치를 부여하여 보팅을 하고 싶었지만, 제출 마감이 얼마 남지 않아서 시도하지 못하였다.

- 0.85를 뚫지 못하다가 보팅을 통해 0.87의 성능을 달성했다.
결과 및 소감
결과
- 최종 성적은 42팀 중 17등을 기록하였다. 15등까지가 A를 받을 수 있기에 다소 아쉬웠지만, 지난 kaggle competition때는 29등을 기록한 것에 비해서는 꽤 발전했다고 할 수 있다.
새롭게 배운 것
- 순수한 성능 경쟁이라면 트렌드와 SOAT 모델을 아는 것이 중요하다.
- 상위권을 기록한 대부분의 조는 klue-bert라는 모델을 사용하였는데, KoBERT의 발전된 버전이지만 단순히 몰랐다는 이유로 사용하지 못했다.
- 데이터의 특성을 파악하고 맞는 모델을 가져오는 것이 중요하다.
- 이번에 주어진 데이터는 노이즈가 많고, 구어체의 정제되지 않은 데이터 형태였다.
- 여기에 맞도록 네이버 뉴스의 댓글, 대댓글을 학습한 KrELECTRA 모델을 사용한 조가 있었고, 역시 상위권을 기록하였다.
- 무턱대고 모델을 가져오는 것이 아니라 데이터 특징에 맞는 모델을 가져왔다는 점이 인상깊었고, 이를 잘 가져오기 위해서는 모델에 대한 지식이 필수라는 것을 깨달았다.
- 항상 최신 모델이 만능은 아니다.
- 당장 우리 조에서도 오직 Dense 레이어만을 이용한 DNN 모델이 가장 성능 점수가 높았다.
- 또한 상위권 입상 조에는 간단한 1DCNN 모델을 직접 구현하여 상위권을 기록한 조도 있었다.
- 최신 모델을 맹신하지 말고 문제에 맞는 모델을 탐색하는 것이 중요하다는 것을 깨달았다.
This post is licensed under CC BY 4.0 by the author.