Aivle Til 230414 5차 미니프로젝트 정리
Aivle Til 230414 5차 미니프로젝트 정리
title: AIVLE TIL (‘23.04.14) 5차 미니프로젝트 정리 date: 2023-04-14 12:42:39.192 +0000 categories: [AIVLE] tags: [‘aivle’] description: 첫 개인 별 캐글 경진대회 image: /assets/posts/2023-04-14-aivle-til-230414-5차-미니프로젝트-정리/thumbnail.png
Kaggle 전략
- 지난 2일간 배웠던 것은 크게 2개로 정리할 수 있다.
- Feature Importance를 이용한 다양한 데이터 탐색 방법
- 문제 하나를 여러 단계의 문제로 쪼개 서로 다른 모델을 학습하는 방법
- 이번 Kaggle 경진대회에서는 이 두 가지 전략을 집중 사용해보고자 하였다.
- 하지만 데이터셋에서 주어진 컬럼이 단 50여개로, Feature Extraction을 하기엔 턱없이 부족한 수였다. (이전에 500여개로 이루어진 칼럼을 받았을 때, 컬럼 개수가 대체로 70개쯤 미만이 되면 성능이 감소하는 현상이 있었다)
- 때문에 FI를 살피고, 중요한 특징만을 선택하는 전략 대신, 딥러닝을 통해 기존의 Feature로 부터 새로운 특징을 만들어내는 Feature Representation을 이용하기로 하였다.
문제를 여러개로 쪼개기
- 주어진 문제의 클래스는 인간의 행동을 나타내는데, ‘걷기’, ‘계단 오르기’, ‘계단 내려가기’, ‘서있기’, ‘앉아있기’, ‘누워있기’의 6가지가 있다.
AutoGluon
AutoGluon은 아마존에서 공개한 오픈소스 머신러닝 자동화 툴 킷으로, 기본적인 모델부터 LightGBM, CatBoost와 같은 SOTA 모델까지 탐색하여 최적의 모델 및 파라미터를 찾아준다.
지난 Dacon 경진대회 때 1위를 기록한 참가자가 별 다른 전처리 없이 AutoGluon을 사용했다는 것이 인상적이었기 때문에 이를 사용하기로 하였다.
동적 동작 vs 정적 동작
'걷기', '계단 오르기', '계단 내려가기'를 한데 묶어 동적 동작,'서있기', '앉아있기', '누워있기'를 한데 묶어 정적 동작으로 구분할 수 있다.
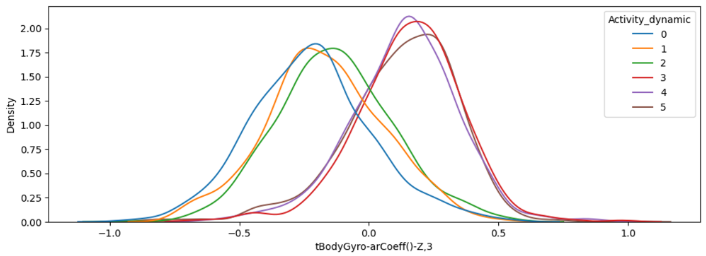
- 데이터를 확인해보면 명확히 알 수 있는데, 0~2(동적), 3~5(정적)끼리의 데이터 분포가 확연히 다른 특징들이 많이 존재한다.
- 즉 먼저 동적, 정적 동작을 구분하는 이진 분류문제를 풀고, 나뉜 데이터에 대해 각각 클래스 3개의 다중 분류 문제를 풀어보는 전략을 취할 수 있다.
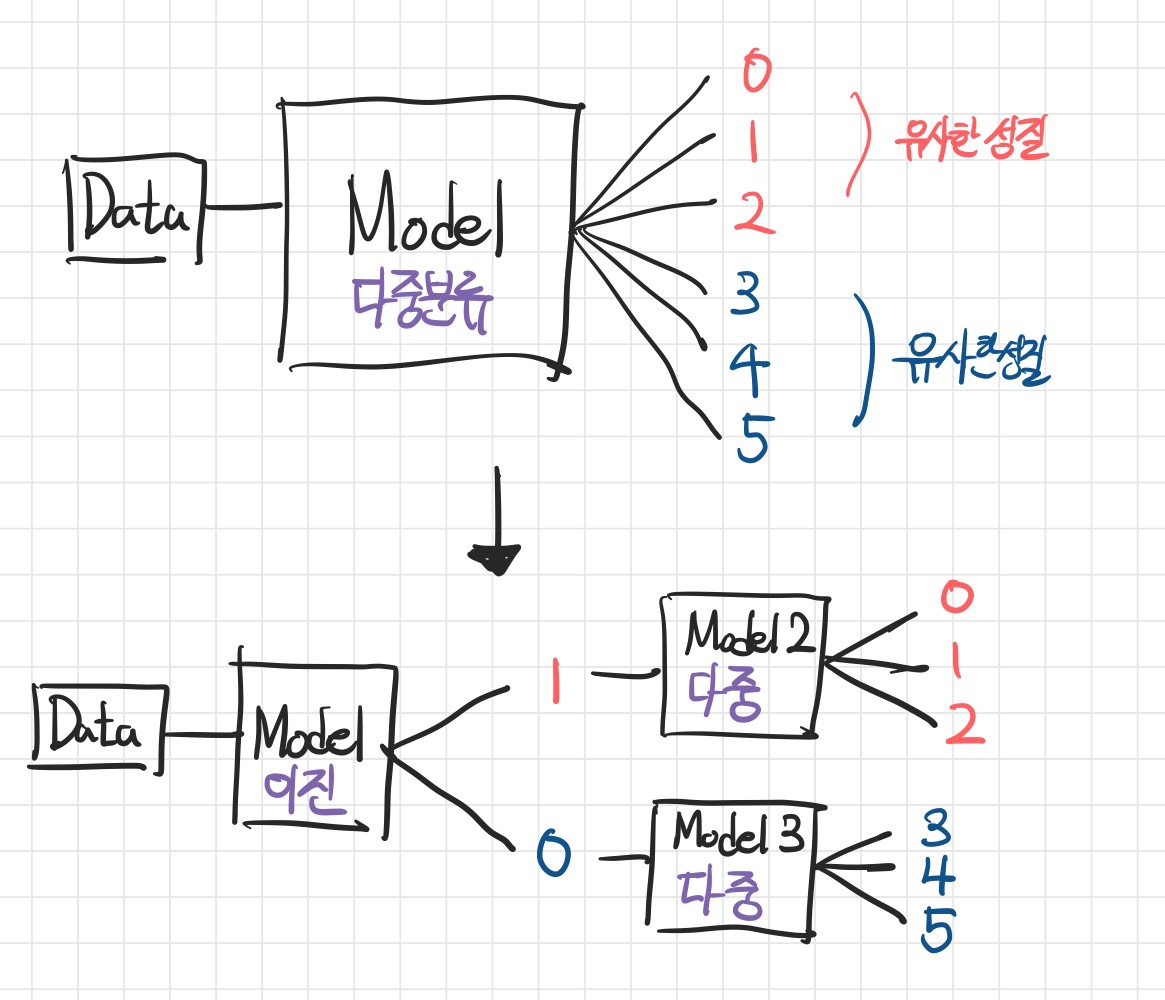
- 그림을 그려보면 이와 같다.
코드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
def get_answer(df_train, df_test):
## AutoGluon에 넣기 위해 데이터프레임을 쪼갬
# is_dynamic 이진분류
df_train_bi = df_train.drop(tgt, axis=1)
# 동적, 정적별 다중 클래스 분류
df_train_st = df_train.loc[df_train[tgt2]==0].drop(tgt2, axis=1)
df_train_dy = df_train.loc[df_train[tgt2]==1].drop(tgt2, axis=1)
## 이진분류 모델 생성
# 모델 설정
predictor = TabularPredictor(label=tgt2, problem_type='binary', eval_metric='f1_macro')
# 학습
predictor.fit(df_train_bi)
# 예측하기
y_pred_bi = predictor.predict(df_test)
# 예측값을 원래 데이터에 합병
temp = pd.concat([df_test, y_pred_bi], axis=1)
# 합병된 데이터에서 예측값을 바탕으로 데이터 분리
df_test_st = temp.loc[temp[tgt2]==0].drop(tgt2, axis=1)
df_test_dy = temp.loc[temp[tgt2]==1].drop(tgt2, axis=1)
del temp
## 다중 분류
# 다중분류(정적) 모델 설정
predictor_st = TabularPredictor(label=tgt, problem_type='multiclass', eval_metric='f1_macro')
# 학습
predictor_st.fit(df_train_st, num_gpus=1)
# 예측하기 (수동 평가)
y_pred_st = predictor_st.predict(df_test_st.drop('ID', axis=1))
# 예측값을 테스트 데이터에 추가
df_test_st['Activity'] = y_pred_st
# 다중분류(동적) 모델 설정
predictor_dy = TabularPredictor(label=tgt, problem_type='multiclass', eval_metric='f1_macro')
# 학습
predictor_dy.fit(df_train_dy, num_gpus=1)
# 예측하기 (수동 평가)
y_pred_dy = predictor_dy.predict(df_test_dy.drop('ID', axis=1))
# 예측값을 테스트 데이터에 추가
df_test_dy['Activity'] = y_pred_dy
## 정답추출
# 테스트 데이터에 ID열을 기준으로 병합(merge)
return pd.concat([df_test_st, df_test_dy])[['ID', 'Activity']]
# 병합된 칼럼에서 정답 및 ID가 포함된 정답칼럼 추출
df_answer = pd.merge(df_test, temp, on='ID')[['ID', 'Activity']]
del temp
return df_answer
- AutoGluon을 수행한 과정이다. 제출 양식에 맞추기 위해 ID를 기준으로 병합하는 과정을 추가하였다.
결과
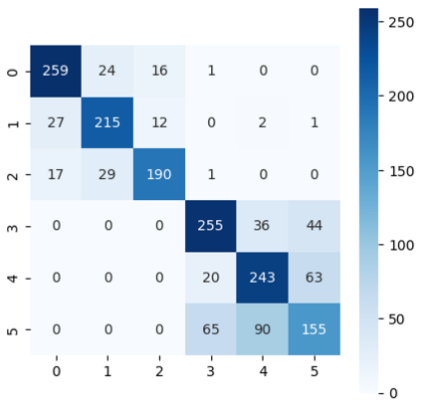
- 4, 5가 바로 앉아있는 상태와 서있는 상태인데, 이 두 클래스를 굉장히 맞추기 어려워하는 경향이 있었다.
One & Rest
- 위 결과를 바탕으로 ‘STANDING’ 클래스인지 아닌지를 먼저 구분하고, 남은 5개의 클래스를 다중분류 해보는 것이 어떨까라는 생각을 하였다.
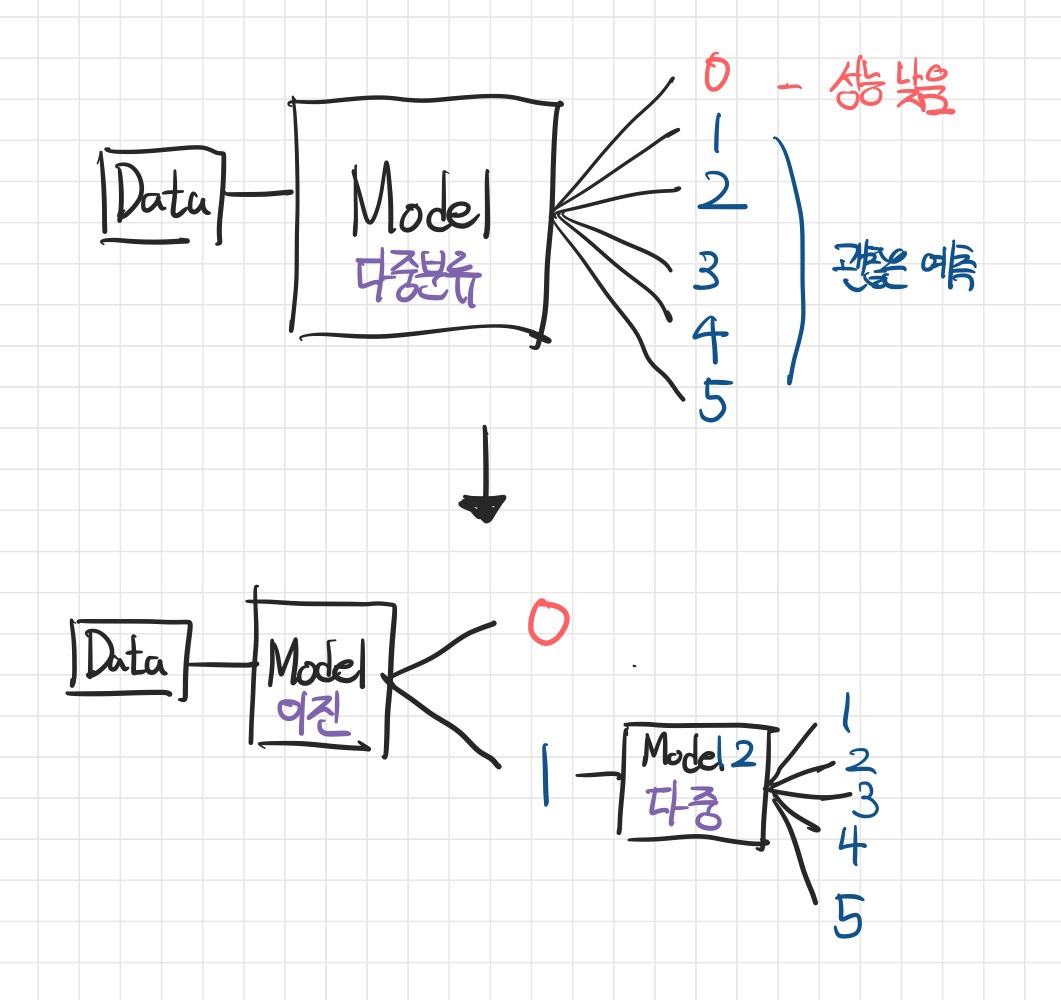
- 코드는 위 코드의 변형과정이므로 생략하고 결과만 보면 다음과 같다.
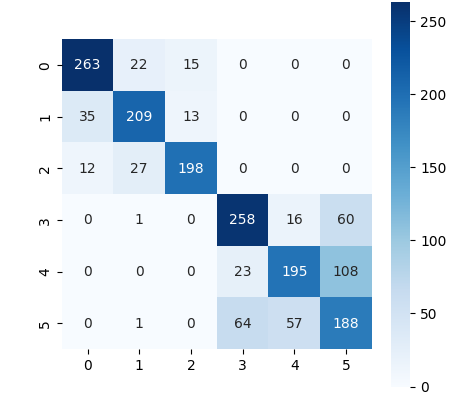
- 4번 클래스가 바로 ‘STANDING’ 클래스인데, recall이 꽤 감소한 것을 확인할 수 있었다. 대신 다른 클래스의 분류 정확도가 상승하여 결과적으로 비슷한 성능을 보였다.
Two & Rest
- 4, 5번 클래스를 모델이 특히 헷갈려하는 것 같아, 이 둘을 묶은 클래스에 속하는지 아닌지에 대한 이진분류 문제를 풀고, 다시 4, 5를 나누는 이진분류 문제와, 0~3을 구분하는 다중분류 문제를 풀도록 하였다.
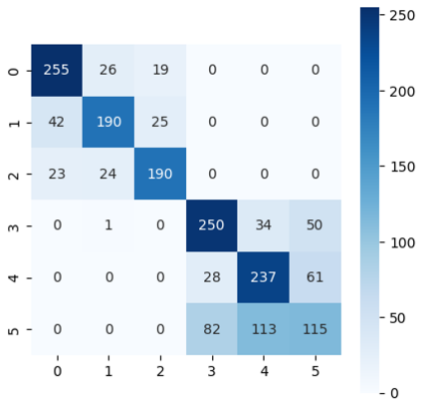
- 결과적으로 가장 우수한 성능을 낸 전략이었다.
딥러닝
사용 레이어
- 기본적인 Dense Layer, Dropout Layer를 사용하여 딥러닝 모델링을 진행했다.
- 대신 에이블 강의시간에 모델의 학습률에 주기성을 부여하면 더 좋은 성능을 얻을 수 있다는 것을 배워 직접 시도해보는 것을 추가하였다.
스케줄러 - CosineDecayRestarts
1
2
3
4
5
6
7
8
tf.keras.optimizers.schedules.CosineDecayRestarts(
initial_learning_rate,
first_decay_steps,
t_mul=2.0,
m_mul=1.0,
alpha=0.0,
name=None
)
- 텐서플로우에서 제공하는 학습률 스케줄러이다.
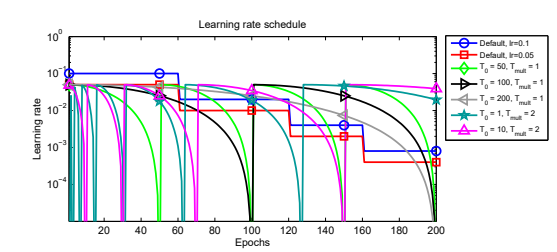
- 이와 같이 learning rate를 코사인 곡선을 따라 감소시키다가
alpha에 도달하면 다시 처음 learning rate로 hard restart하는 스케줄러이다. initial_learning_rate: 학습률의 시작점first_decay_steps:alpha까지 몇 step(epoch)에 걸쳐 도달할지t_mul: restart가 이루어 질 때마다first_decay_steps에t_mul만큼을 곱한다. t_mul이 2.0일 경우, 50 -> 100 -> 200 순으로 decay_step이 상승한다.m_mul: restart가 이루어 질 때initial_learning_rate에m_mul만큼을 곱한다. m_mul이 0.5일 경우 1e-3 -> 5e-4 -> 2.5e-4 순으로 재시작 시 학습률이 변한다.alpha: 학습률의 최저점
코드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
from tensorflow.keras.backend import clear_session
from tensorflow.keras.layers import Input, Dense, Dropout
from tensorflow.keras.models import Model
from tensorflow.keras.callbacks import EarlyStopping, LearningRateScheduler
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.optimizers.schedules import CosineDecayRestarts
# Define the CosineAnnealingWarmRestarts schedule
schedule = CosineDecayRestarts(initial_learning_rate=1e-3,
first_decay_steps=50,
t_mul=2.0,
m_mul=0.6,
alpha=1e-6
)
# Define the optimizer with the initial learning rate
optimizer = Adam(learning_rate=schedule)
es = EarlyStopping(monitor='val_loss',
min_delta=0,
patience=100,
verbose=1,
restore_best_weights=True)
# 세션 클리어
clear_session()
# 레이어 연결
il = Input(shape=(len(x_train.columns),))
hl = Dense(256, activation='swish')(il)
hl = Dense(128, activation='swish')(hl)
hl = Dense(256, activation='swish')(hl)
hl = Dropout(0.2)(hl)
hl = Dense(512, activation='swish')(hl)
hl = Dropout(0.2)(hl)
hl = Dense(1024, activation='swish')(hl)
hl = Dropout(0.2)(hl)
hl = Dense(512, activation='swish')(hl)
hl = Dropout(0.2)(hl)
hl = Dense(256, activation='swish')(hl)
hl = Dropout(0.2)(hl)
ol = Dense(6, activation='softmax')(hl)
# 모델 선언
model = Model(il, ol)
# 컴파일
model.compile(loss=keras.losses.sparse_categorical_crossentropy,
metrics=['accuracy'],
optimizer=optimizer)
# 요약
model.summary()
model.fit(x_train, y_train, epochs=1000, verbose=1, validation_split=0.2, callbacks=[es])
결과
- 모델을 깊게도 쌓아보고, 얕게도 쌓아봤으나 4, 5를 여전히 구분하지 못하는 성능을 내었다.
- 남은 시간이 얼마 없었기에 이 이상 딥러닝에 많은 시간을 투자하지 못하였다.
후기
최종 결과
- 285명 중 99등을 기록하여 이번에도 상위 30% 이내에 드는 것은 실패하였다.
- 지난번 팀 프로젝트 때와 같이 다소 아쉽게 순위권을 놓쳤는데, 다음 미니 프로젝트때는 꼭 30% 이내에 들어보고 싶다.
아쉬웠던 점
- 컬럼이 생각보다 적게 주어져 FI를 이용해볼 수 없었던 점이 아쉬웠다.
- 또한 AutoGluon을 매우 기본적인 단계로 사용해서 충분한 성능을 뽑아보지 못한 것이 아쉬웠다. 경진대회가 끝날 때즘 fit에 여러가지 인자를 주어 튜닝할 수 있다는 것을 알았으나, 이미 시도하기 늦은 상황이었다.
새롭게 알게 된 점 (앞으로 배워야 할 것)
wandb
- 매번 모델을 돌릴 때마다 결과를 정리하고, 기록하는 것이 어려웠는데 이번에 다른 에이블러님의 발표에서
wandb라는 것을 알게되었다. - 이번 미니 프로젝트를 통해 결과를 기록 및 분석하는 것이 정말 중요하다는 것을 깨달았는데, 이참에 wandb를 배워서 다음 미니 프로젝트 때 써먹어봐야겠다.
autogluon 튜닝
- 학습(fit)을 할 때 몇가지 인자를 주는 것을 통해 모델을 손쉽게 튜닝할 수 있다는 것을 알게 되었다.
- 추후 공식문서를 읽고 AutoGluon을 사용할 때 다양한 튜닝 옵션을 적용해봐야겠다. (개인 캐글 경진대회 등을 참여하는 것도 좋을 것 같다)
This post is licensed under CC BY 4.0 by the author.