Til 부스트코스 최적화의 주요 용어 이해하기 강의 정리
title: [TIL] 부스트코스 최적화의 주요 용어 이해하기 강의 정리 date: 2023-01-02 11:19:59.315 +0000 categories: [부스트코스] tags: [‘프리코스’] description: 용어를 정확히 정의하지 않으면 의사소통에서 많은 오해가 생길 수 있기 때문loss function이 줄어드는 방향을 편미분을 통해 찾고, 그 방향으로 일정 수치(학습률)만큼 이동하는 것을 반복하며 학습하는 방법local minimum 값을 찾을 수 있다.학습이 진행될수 image: /assets/posts/2023-01-02-til-부스트코스-최적화의-주요-용어-이해하기-강의-정리/thumbnail.png
Introduction
용어를 알아야 하는 이유
- 용어를 정확히 정의하지 않으면 의사소통에서 많은 오해가 생길 수 있기 때문
Gradient Descent (경사하강법)
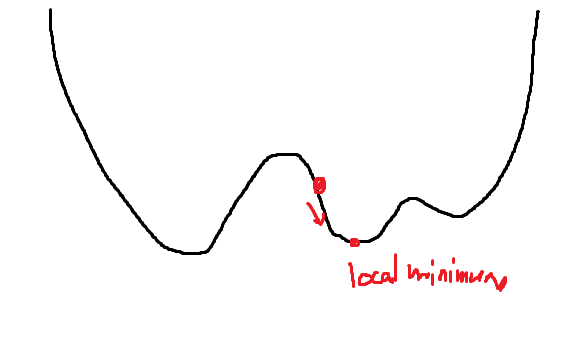
- loss function이 줄어드는 방향을 편미분을 통해 찾고, 그 방향으로 일정 수치(학습률)만큼 이동하는 것을 반복하며 학습하는 방법
- local minimum 값을 찾을 수 있다.
Optimization 용어 정리
Generalizatin(일반화)
학습이 진행될수록 학습 데이터에 대한
training error는 감소한다.하지만 학습이 어느정도 이상 지나면 학습에 사용하지 않은 테스트 데이터에
test error는 오히려 증가할 수 있다.여기서 training error와 test error 사이의 차이를
Generalization gap(일반화 성능)이라 한다.일반화 성능이 높다고 해서 테스트 데이터에 대한 절대 성능이 높다는 것은 아니다. (학습 데이터에 노이즈가 많을 수도 있으므로)
Underfitting & Overfitting
- 주로 선형회귀를 설명할 때 쓰이는 이론적인 용어이다.
Underfitting
- 학습이 충분히 이루어지지 않아 학습데이터에 대한 성능도 낮은 상태
Overfitting
학습이 너무 많이 이루어져 학습데이터에 대한 성능은 높지만, 테스트 데이터에 대해 잘 작동하지 않는 상태
둘 사이의 밸런스 상태를 찾아야 하는 것이 기본이다. 하지만 overfitting이 오히려 target일 가능성도 있기 때문에 이론적으로만 사용되는 용어이다.
Cross-validation
Validation data
학습 데이터를 모두 학습에 사용하지 않고, 일부분을 validation data(검증 데이터)로 사용하여 학습 후 모델의 성능을 검증하는 방법이다.
하지만 학습 데이터가 고정되어있을 때 검증 데이터가 많을수록 학습에 사용할 데이터는 감소하므로, 학습의 정도가 감소할 수 있다.
이러한 단점을 극복하기 위해
Cross validation을 사용한다.
Cross-validation
학습 데이터 전체를 K개의 블록으로 나누어 이중 K-1개를 학습에 사용하고, 나머지를 검증 데이터로 사용하는 방법이다.
예시
- K = 5
- 학습 : 1, 2, 3, 4 검증 : 5
- 학습 : 1, 2, 3, 5 검증 : 4
- 학습 : 1, 2, 4, 5 검증 : 3 …
이런식으로 여러번 교차검증이 가능하다.
- 주로 최적해에서 찾고 싶은 값인
hyper parameter를 찾기 위해 사용하는 방법이다.- hyper parameter : 모델링 시 사용자가 직접 세팅하는 값
- hyper parameter set를 찾고 고정한 후에는, 모든 학습데이터를 사용하여 학습을 진행한다.
Bias & Variance
Bias
- true target과 모델의 output의 평균값이 얼마나 떨어져있나를 나타내는 척도
- bias가 낮을수록 true target과 가깝다는 뜻이다.
Variance
- 출력의 일관성을 나타내는 척도 (통계에서 분산과 비슷하다)
- variance가 낮을수록 출력이 일정하다는 뜻이다.
Bias와 Variance의 tradeoff 관계
- 학습데이터에 노이즈가 있다는 가정하에, 최적화를 통해
cost를 최소화하는 데에는 한계가 있다. - 즉 bias가 낮을수록 variance가 높을 가능성이 크고, variance가 낮을수록 bias가 높을 가능성이 크다.
cost = bias^2 + variance + noise
Bootstrapping
고정된 학습 데이터에서 학습 데이터의 일부만 샘플링하는 방식으로 여러개의 학습 데이터를 만들어 학습을 시키는 방법이다.
각각의 학습데이터마다 모델을 여러개 만든다. (random)
최종적으로 만들어진 여러개의 모델에 같은 입력을 넣고, 각 모델의 출력값이 얼마나 일치하는지를 확인한다.
이를 통해 전체 모델의
Uncertainty(측정불확도)를 확인할 수 있다.
Bagging
- Bootstrapping aggregating의 약자이다.
- bootstrapping을 통해 학습한 여러개의 모델(weak learner)을 voting 또는 averaging하여 strong learner를 예측한다.
Boosting
- 순차적인 방법을 따라 여러개의 모델을 만들어 strong learner를 찾는 방법이다.
- 어떤 weak learner 모델을 만들어 학습 데이터로 테스트를 해본다.
- weak learner가 잘 분류하지 못한 일부 데이터를 새로운 학습 데이터로 새로운 모델을 만든다.
- 이 과정을 반복하여 여러개의 모델을 만든다.
- 여러개의 weak learner를 통해 strong learner를 찾는다.